How Can We Help?
Overview of Pipeline Types
Machine Learning Pipelines are a way to automatically transform raw data into machine learning predictions. Cortex is a platform that allows anyone within an organization to easily create predictions based on data that has already been captured. Below, we will go over the different pipeline types available within Cortex, and list some examples to give a better understanding of what is possible.
Which Pipeline Should I Use?
Cortex offers multiple pipeline and prediction types. The following diagram will help explain which pipeline type is best suited for different predictions.
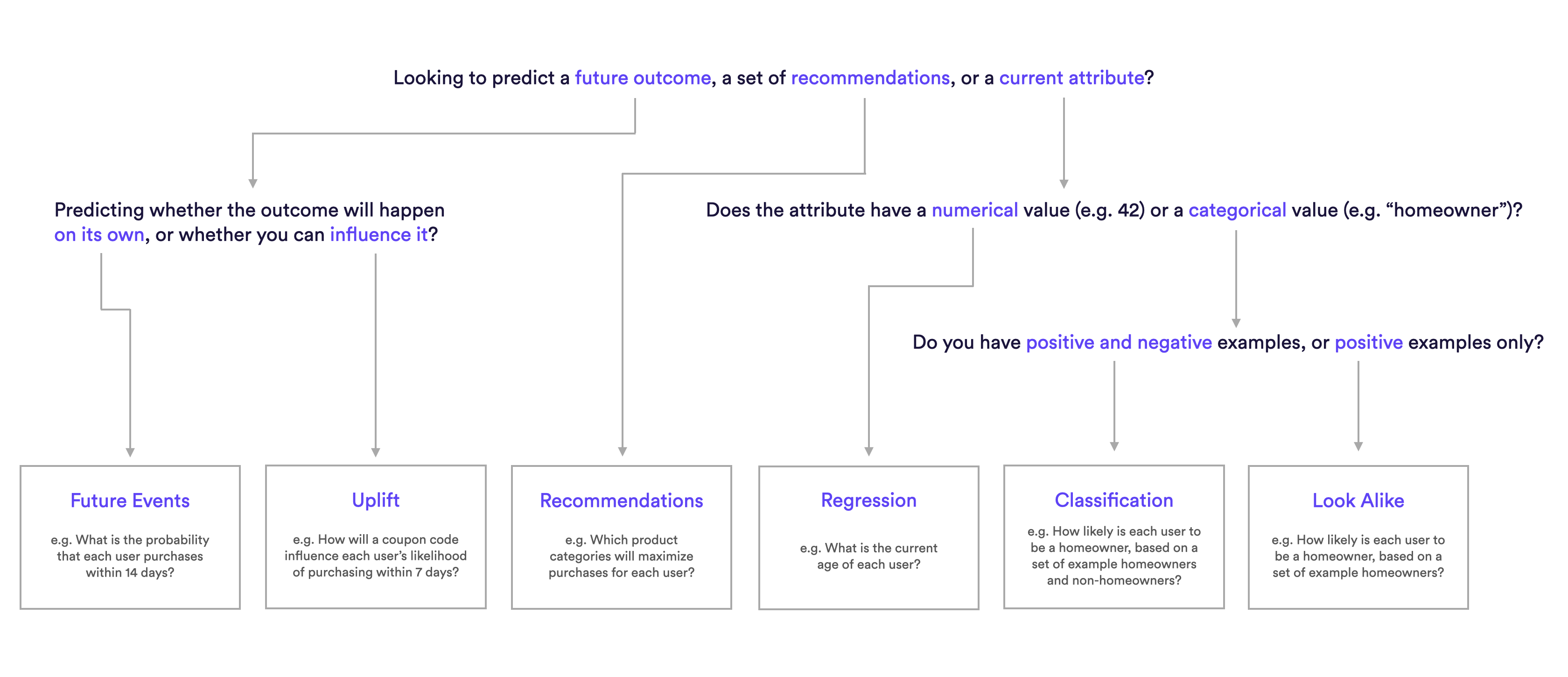
Future Events Pipelines
Describe an event in everyday terms, and Cortex will predict the likelihood that each user completes that event in the future. If you can describe it with your data, you can predict it in Cortex – any type of event, any set of conditions, and any future window of time. Learn how to build your own Future Events Pipeline.
Future Event Pipeline Examples
- What is the probability that each user purchases from category “shoes” within 7 days?
- What is the probability that each user will take any action within the next 30 days?
- What is the probability each Visitor to our site will Subscribe?
- What is the probability a Lapsed User will Resubscribe?
Uplift Pipelines
Specify a conversion event, and provide details about an intervention designed to drive those conversions. Cortex will predict the impact of your intervention on each user’s likelihood of converting in the future. Learn how to build your own Uplift Pipeline.
Uplift Pipeline Examples
- How will a discount change each user’s likelihood of purchasing within 7 days?
- How will a personalized email influence each user’s likelihood of churn the following month?
- Is each user more likely to subscribe with a free trial or a discounted subscription?
Recommendation Pipelines
Select a set of items that you’d like to recommend. Cortex will learn the unique preferences of your users and generate personalized recommendations for each one. You may also specify a particular type of event for these recommendations to optimize. Learn how to build your own Recommendations Pipeline.
Recommendations Pipeline Examples
- Which articles will maximize CTR onsite for each user?
- Which products will maximize email click through for each user?
- Which video genres will maximize overall engagement for each user?
- Which product categories will maximize purchases for each user?
- Which day-of-week will maximize email opens for each user?
- Which marketing channels will maximize click-through-rate?
Regression Pipelines
Upload a list of users along with values of some numeric attribute. Cortex will predict the value of that attribute for each of your remaining users. Learn how to build your own Regression Pipeline.
Regression Pipeline Examples
- What is the current age of each user, based on an uploaded set of known user ages?
- What is the household income of each user, based on an uploaded set of known user incomes?
Look Alike Pipelines
Upload a list of users which share a common characteristic. Cortex will search through the rest of your users and score each one in terms of how similarly it looks and acts to the uploaded set. If you have a list of users without the characteristic, use a Classification pipeline instead. Learn how to build your own Look Alike Pipeline.
Look Alike Pipeline Examples
- How similar is each user to an uploaded set of homeowners?
- How similar is each user to an uploaded set of first-time homebuyers?
Classification Pipelines
Upload a list of users which share a common characteristic, and another list of users that don’t exhibit the characteristic. Cortex will score each remaining user in terms of its likelihood to belong to the first group rather than the second.
Like Look Alike pipelines, Classification is used to determine whether your users are likely to belong to a certain group. If you have access to negative labels, you should always use a Classification pipeline to solve this type of problem, since negative labels give Cortex more information from which to learn. Learn how to build your own Classification Pipeline.
Classification Pipeline Examples
- What is the likelihood that each user is a homeowner, based on sets of homeowners and non- homeowners?
- What is the likelihood that each user is a student, based on sets of students and non-students?
Related Links
- What is a Machine Learning Pipeline?
- How to Build a Future Events Pipeline
- How to Build a Look Alike Pipeline
- How to Build a Classification Pipeline
- How to Build a Regression Pipeline
- How to Build a Recommendations Pipeline
Still have questions? Reach out to support@mparticle.com for more info!