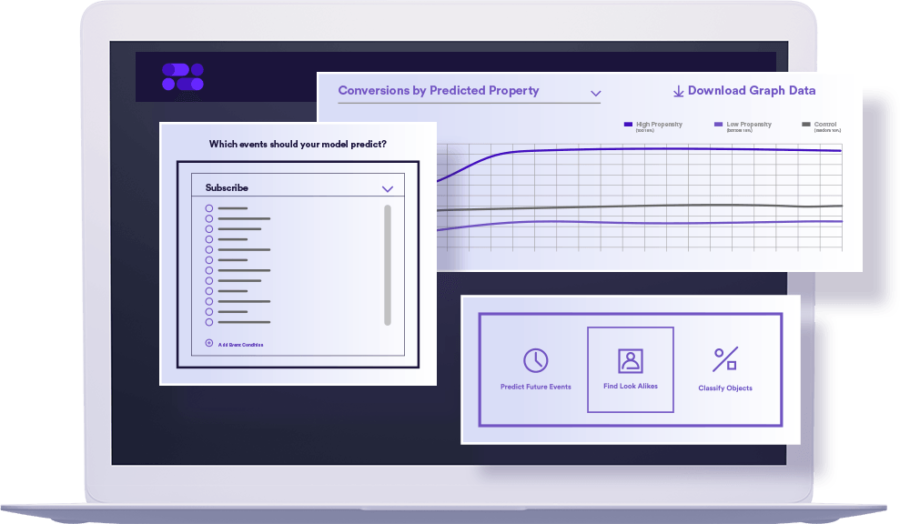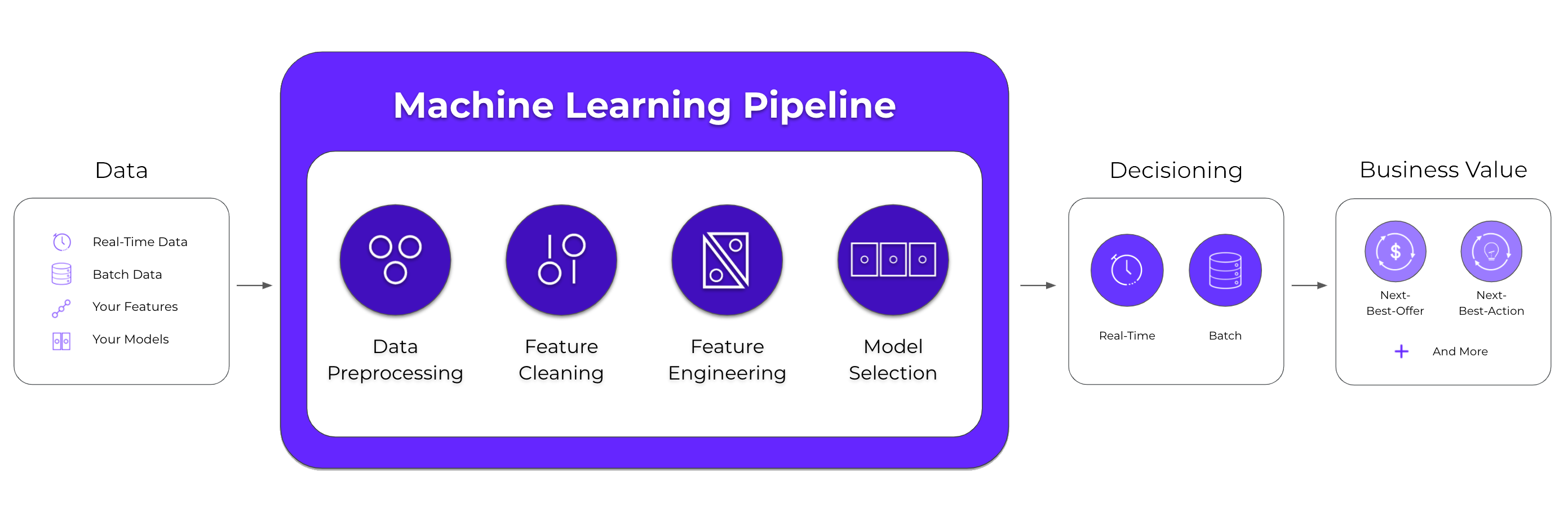

Data Wrangling
Cortex ingests raw behavioral and attribute data at massive scales and provides tools to automatically aggregate and the data.
Feature Engineering
Models learn from features, not raw behavioral data. Cortex's automated feature engineering searches across multiple time windows and nonlinear transformations.

Model Selection
Cortex eliminates guesswork by automatically testing combinations of algorithms and model parameters to build the best pipelines.