How Can We Help?
How to Build a Look Alike Pipeline
Cortex is an easy-to-use platform that enables anyone to automate Machine Learning Pipelines from continuous streams of event data.. In this guide, we’ll show you how to expand small sets of users into audience segments using Look Alike pipelines in Cortex.
What are Look Alike pipelines?
Predictions from a Look Alike pipeline answer the question: how likely is each user to belong to a certain group? Often this group (in ML terms, your positive labels) consists of a small set of users that are known to share a particular trait, allowing you to identify which other users are also likely to exhibit that trait. This lets you take traits that you’ve collected for a small group and leverage them into broad insights about your entire set of users. Learn more about common survey-based use cases for these pipelines here.
Note that while we’ll be using the example of predicting a user attribute, your Cortex account can be configured to make predictions about any type of object tied to your event data (e.g. commerce items, media content, home listings, etc.).
When should I use a Look Alike pipeline?
Whether to use a Look Alike pipeline depends on the prediction value you are looking to receive as well as the data at your disposal. You should use a Look Alike pipeline if –
- Your prediction should answer “Yes/No” question about a user attribute, (e.g. “Is this user a CEO?”. If you’re looking to identify a numeric attribute (e.g. “What is the age of this user?”), use a Regression pipeline instead.
- You have a positive set (users which share the trait you’d like to identify in other users) but do not have access to a corresponding negative set (another group which don’t exhibit this trait). If you only have both positive and negative labels, use a Classification pipeline instead.
The following diagram will help explain which pipeline type is best suited for different predictions.
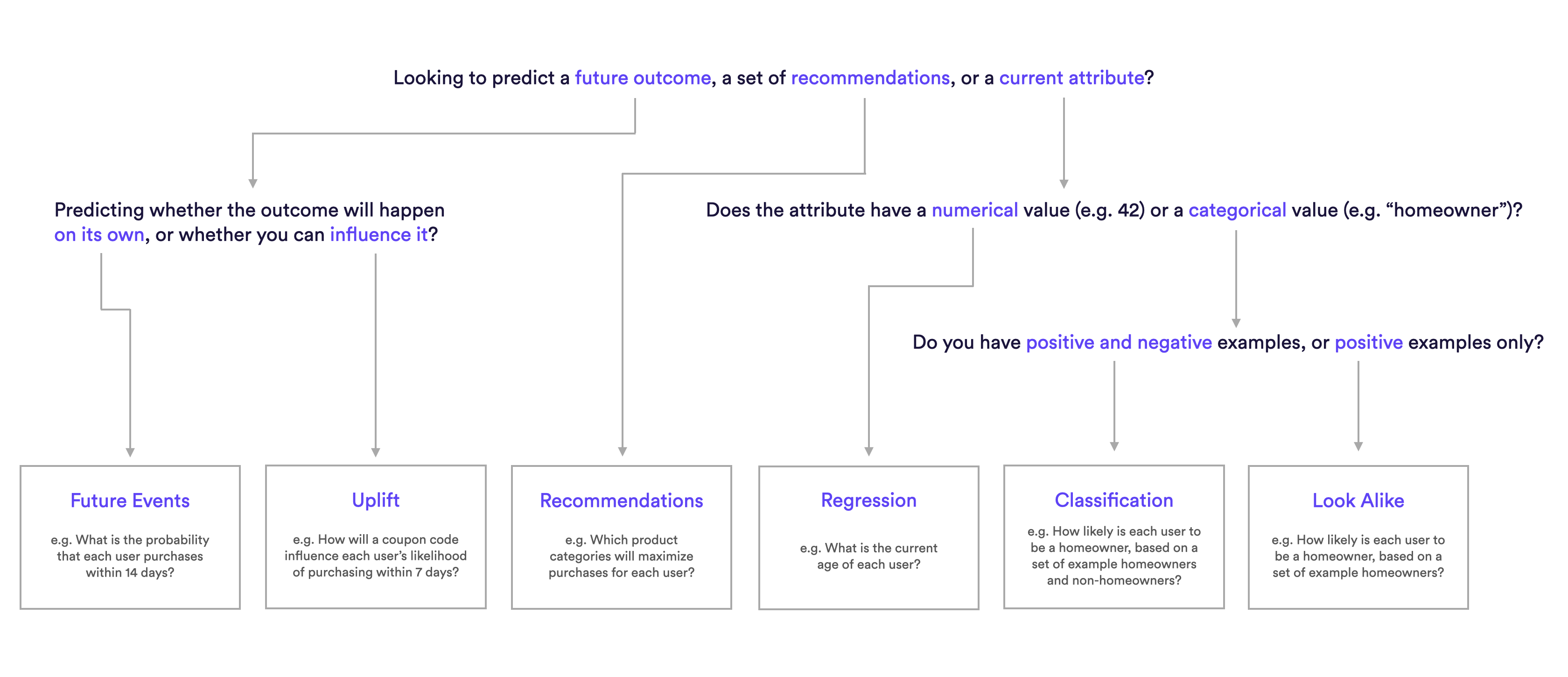
What are Examples of Look Alike pipelines?
Look Alike Pipeline Examples
- How similar is each user to an uploaded set of homeowners?
- How similar is each user to an uploaded set of first-time homebuyers?
How do I build these pipelines in Cortex?
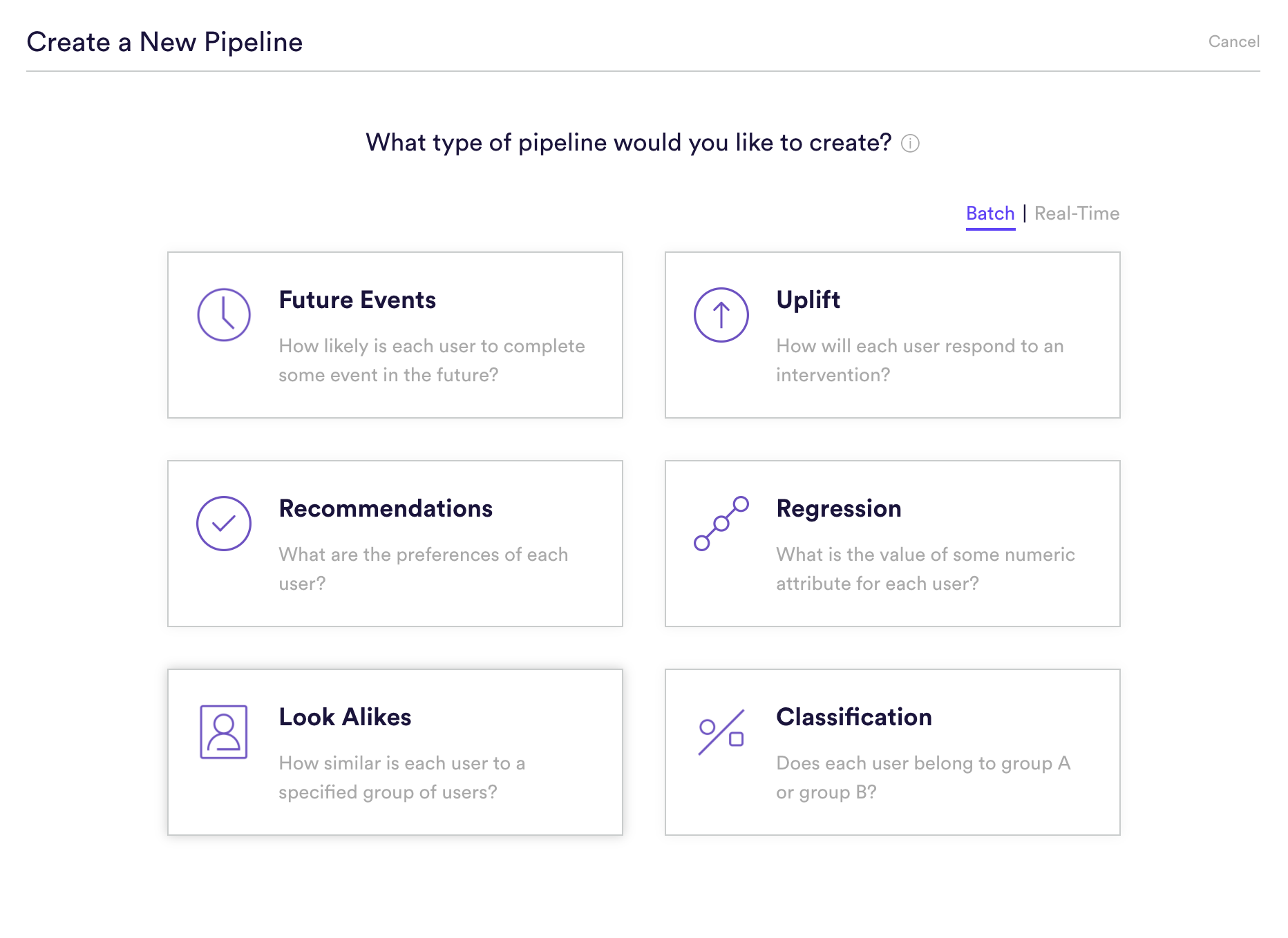
Step 1: Choose Pipeline Type
Select ‘Create New Pipeline’ from your Cortex account. Make sure that the “Batch | Real-Time” toggle is set to “Batch”, and choose the Look Alike pipeline type.
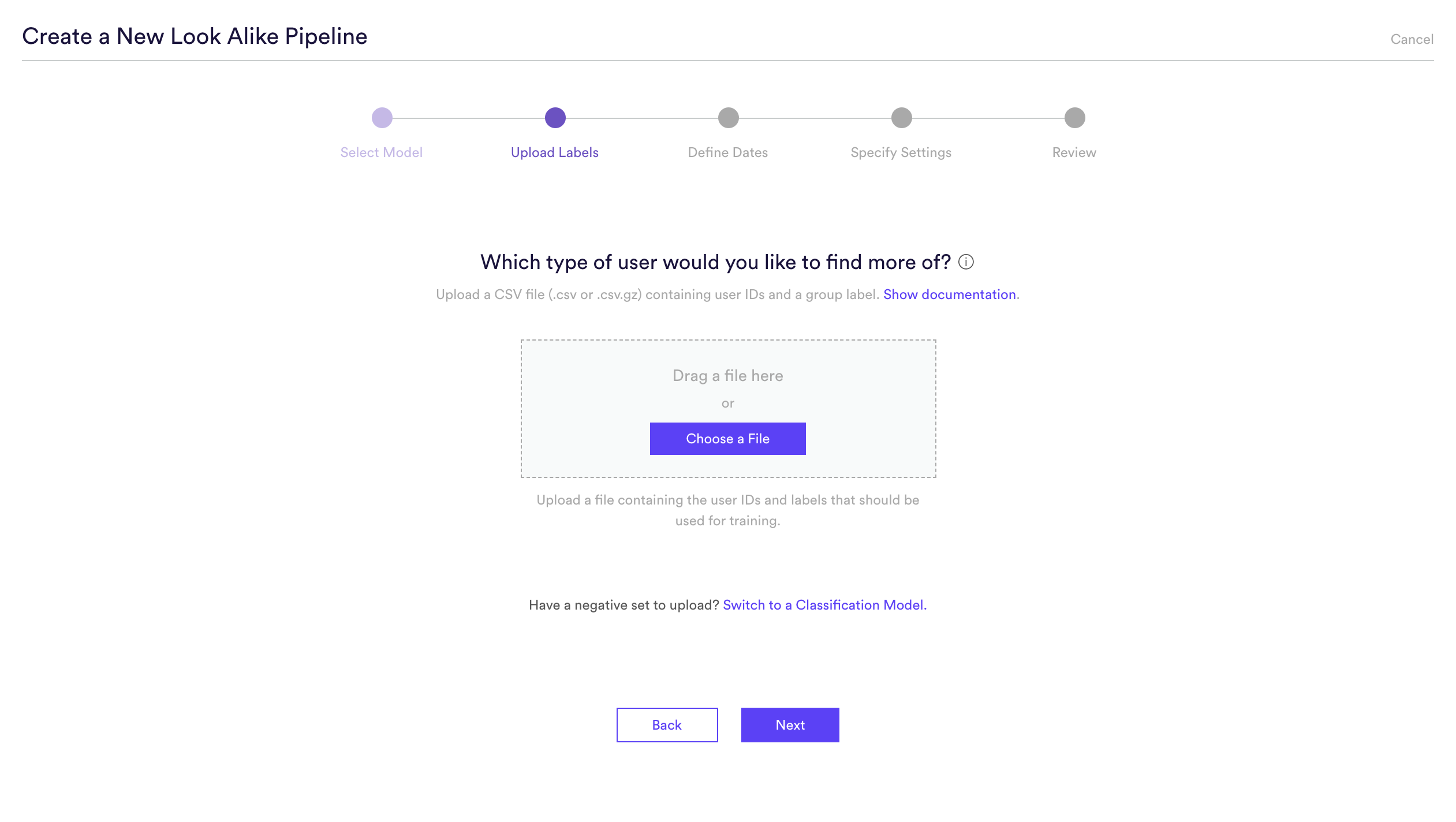
Step 2: Upload Sets
Upload a set of positive user labels, i.e. a list of User IDs of users you already know exhibit the trait you are looking to predict in the rest of your user base, to be used during training. Cortex will find these IDs in your existing event data, learn what attributes and behaviors are associated with each set, and score each remaining user in terms of how similarly it resembles users in the positive set.
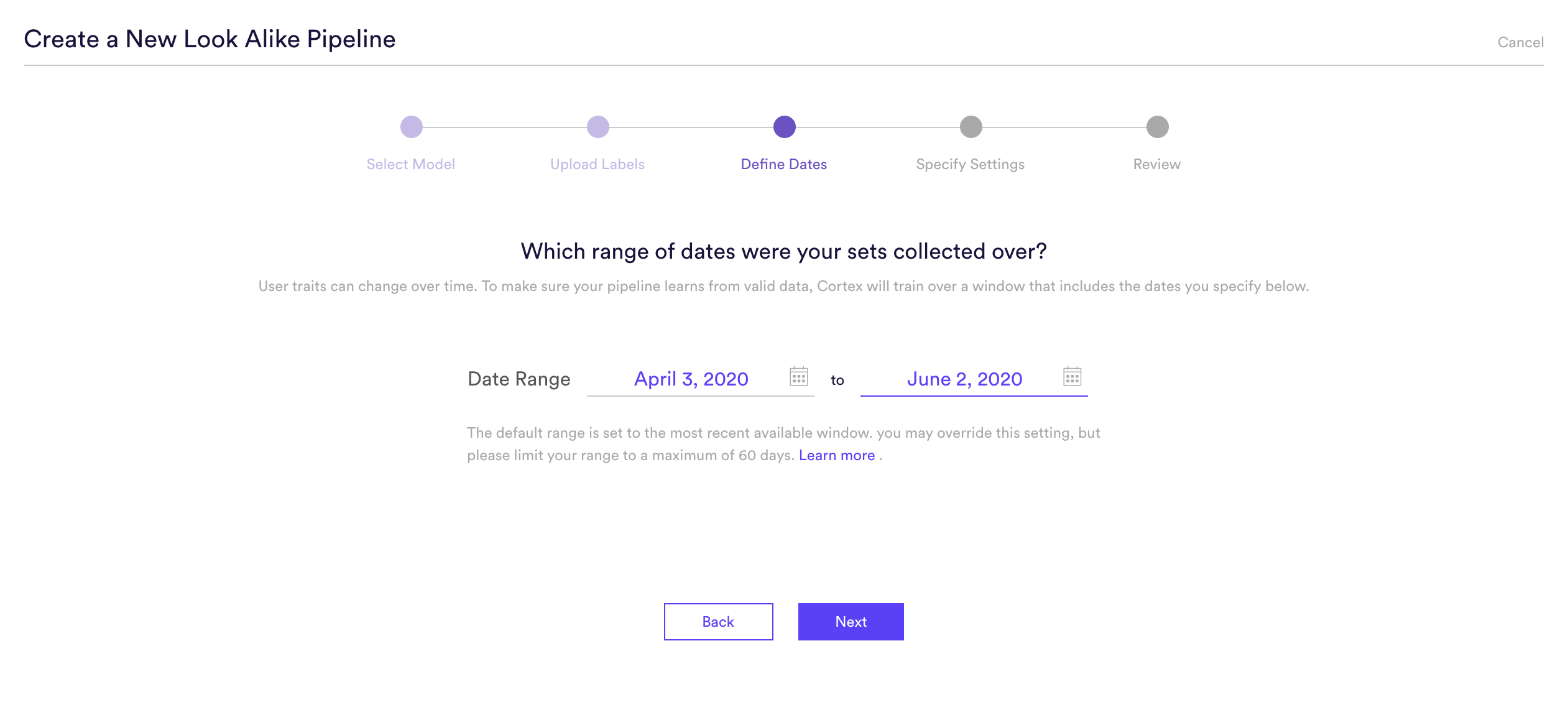
Step 3: Define Dates
Traits can change over time. If the sets that you uploaded were collected in the past, some users may have switched groups over time. To make sure Cortex learns from the right data, define a range of training dates during which your sets are likely to be valid.
By default, your date range will be set to the most recent period.Cortex will use event data recorded between these dates in order to learn. You may want to override this default if there is another window that better satisfies the below conditions –
- Your example sets are likely to be valid. If your examples were collected in the past, sets for some users may be outdated. Find a range when the sets you uploaded are likely to have remained constant.
- Your example users are likely to be active. Cortex learns from event data associated with the IDs you uploaded. In order to provide Cortex as much data as possible, choose a range when the greatest number of your uploaded IDs were active and completing events.
- Event data is likely to reflect the present. If your business’ data has changed over time or contains a lot of seasonality, you should carefully select a range that contains event patterns that are relevant going forward.
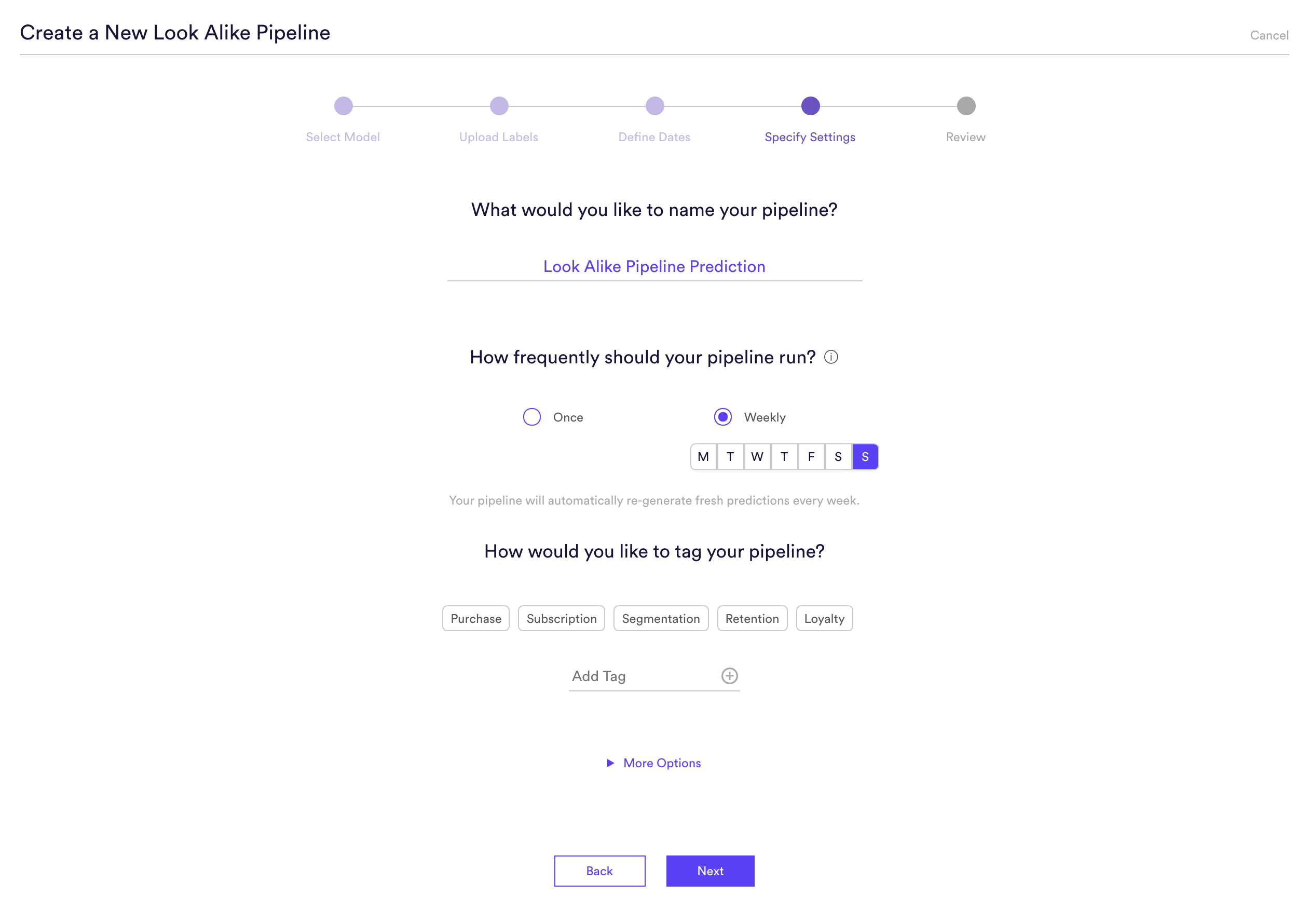
Step 4: Specify Settings
Specify settings such as your pipeline’s name, schedule, tags, and more.
Every time your pipeline runs, Cortex goes through the end-to-end process of generating fresh predictions from the latest data that’s been ingested. If you’d like to power automation based on predictions that are always up-to-date, make sure your pipeline is set to run repeatedly. If you’re just testing things out or building a pipeline for one-time use, your pipeline should only run once.
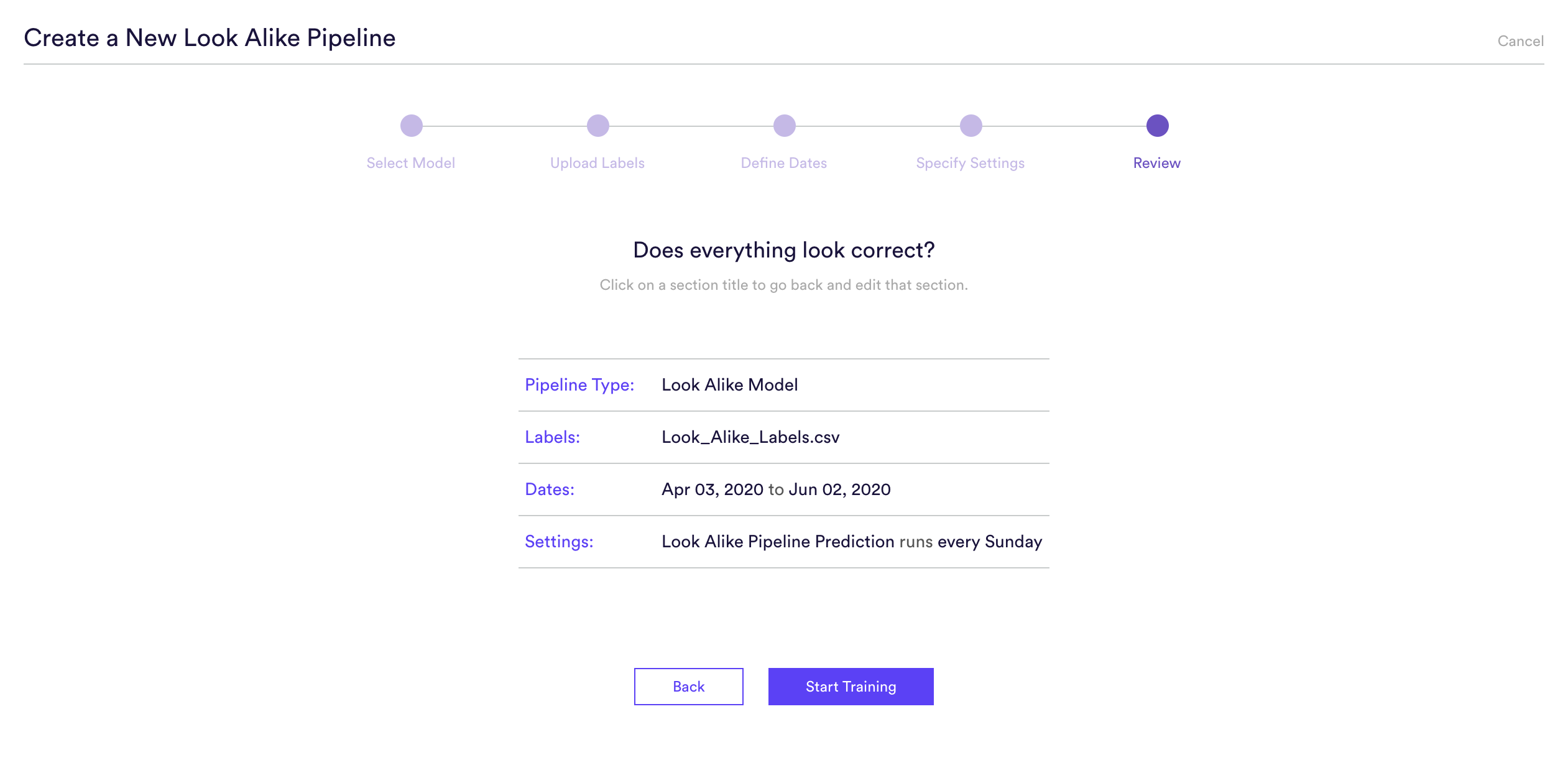
Step 5: Review
The final step is to review your pipeline and ensure all settings look accurate! If anything needs updated, simply go ‘Back’ in the workflow and update any step.
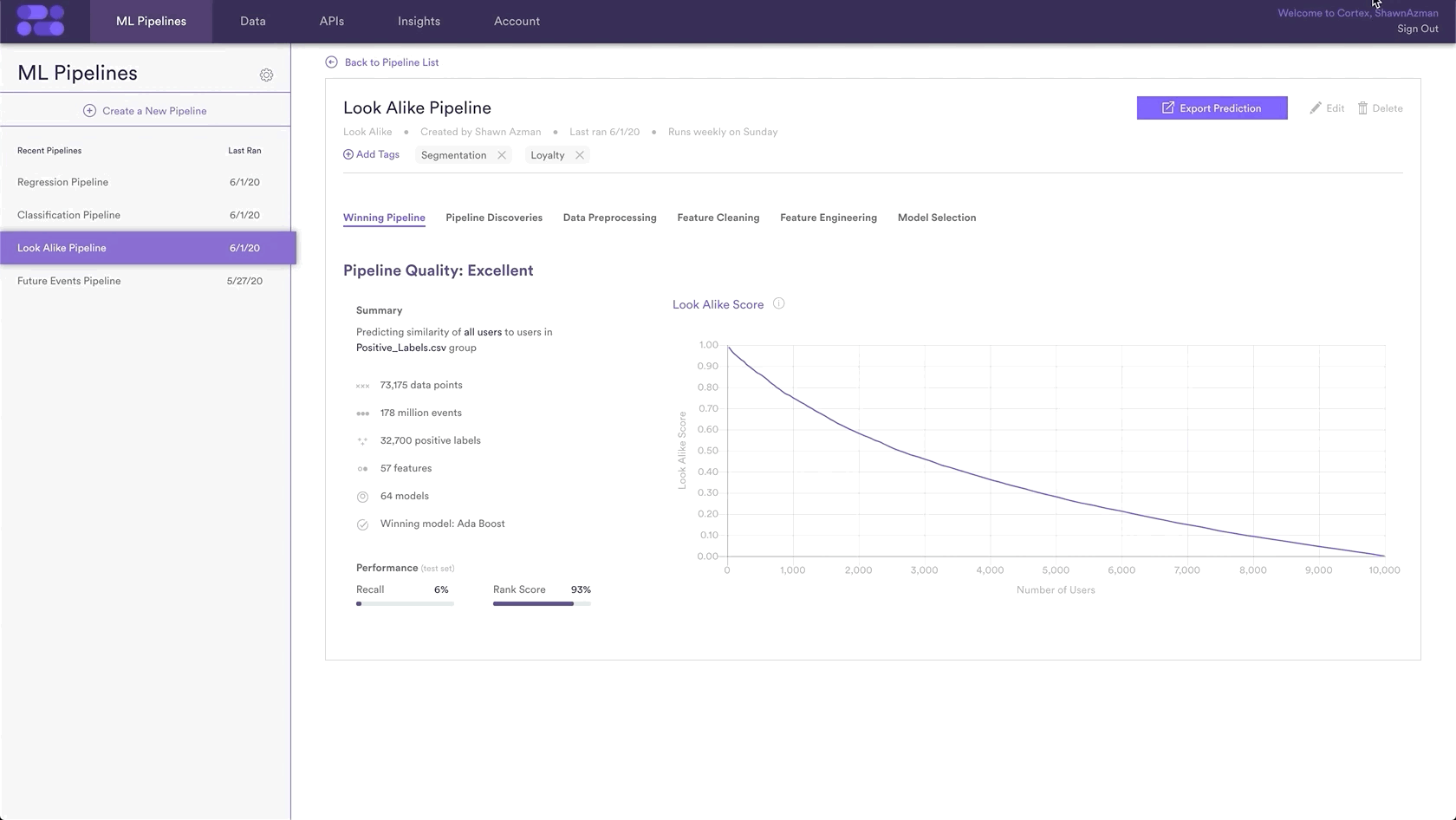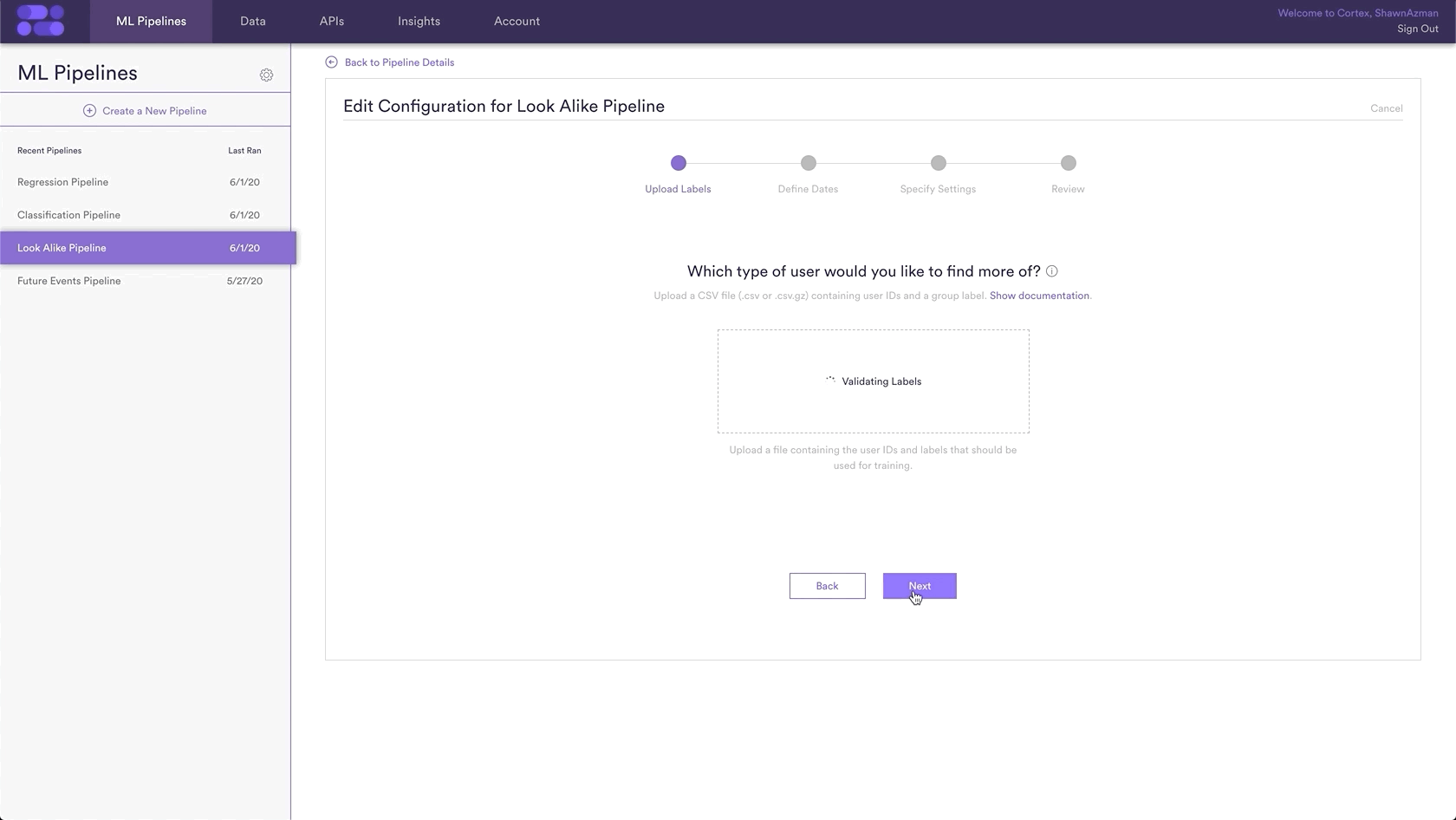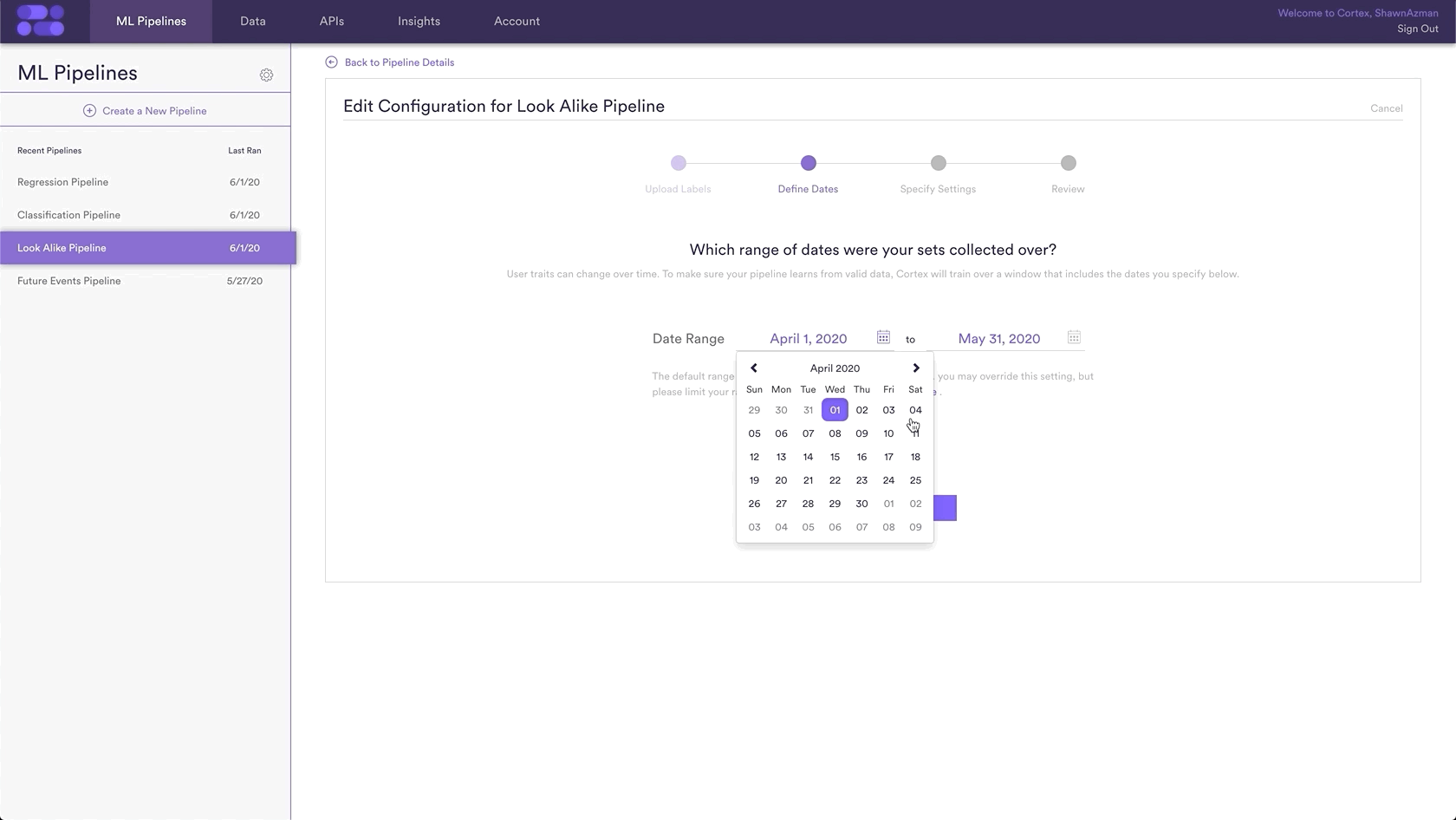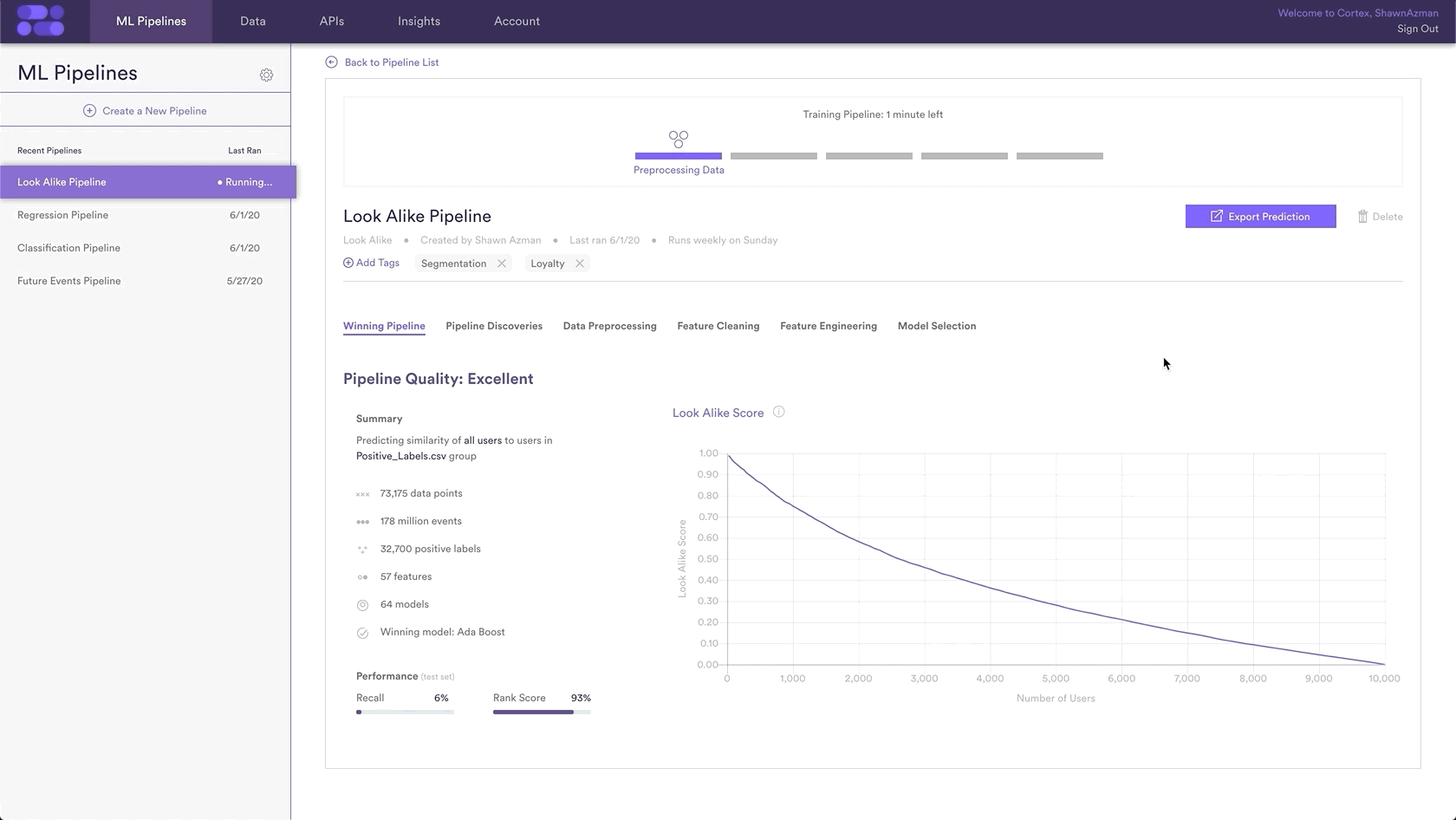
Step 6: Update Labels Over Time (Optional)
If you’re collecting new positive and negative labels over time, you can import these extra labels into Cortex so that your pipelines are always learning from the most recent information. To upload new labels, hit the “Edit” button on your pipeline (next to “Export Predictions”).
Related Links
- Look Alike Performance
- How to Build a Classification Pipeline
- How to Build a Regression Pipeline
- How to Build a Future Events Pipeline
- How to Build an Uplift Pipeline
- How to Build a Recommendations Pipeline
Still have questions? Reach out to support@mparticle.com for more info!