
Knowing who your customers are is the first step to creating a personalized experience for them. However, in reality it is rare that we know every piece of data for every customer of ours. More likely, you have a group of customers for whom you already know this data. The rest of the customers have a Blank or Null value.
Examples of these Customer Attributes could be:
- Demographics (Age/Gender)
- Employment (Job Title)
- Preferred Content (e.g. Sports vs Business in Media)
If you don’t have this information for all of your customers, this typically leads to one of two scenarios
- Smaller Target Audience: if you only have this data for a percentage of your customers and you are looking to have a personalized experience based on that data, one outcome is to only serve that experience to that smaller subset of your customers. This allows you to ensure the experience is tailored to the audience, but it also may limit the overall reach given the incomplete data.
- Less Personalized Experience: the other outcome would be to limit the amount of personalization you do given the lack of a complete picture of your customers. This allows you to serve an experience to 100% of your audience. However, at the cost of the personalization that comes from the utilization of your data.
Obviously, neither of these outcomes gives all of the benefits of being able to personalize for the entirety of your audience. There is a third option however, and that is to predict the missing values using Machine Learning!
Predicting Customer Attributes with Machine Learning
We at Vidora allow businesses to take raw customer behaviors and turn that into predictions. Examples of this would be to Predict Churn or Purchases. However, another way to use Predictions is to take data you already know about a segment of your customers, and use that to predict that same information for the rest of your customers.
The process is simple:
- Identify an Attribute value that you know for a certain percentage of your customers, and that you want to predict for the rest of your customers
- Extract all Customers for whom you know the Attribute value
- Upload those to Vidora’s Look Alike Model as Positive Labels, or to a Classification Model with both Positive and Negative Labels
- Vidora will then, using all behavioral data being sent to us, predict the Attribute value for all other of your customers
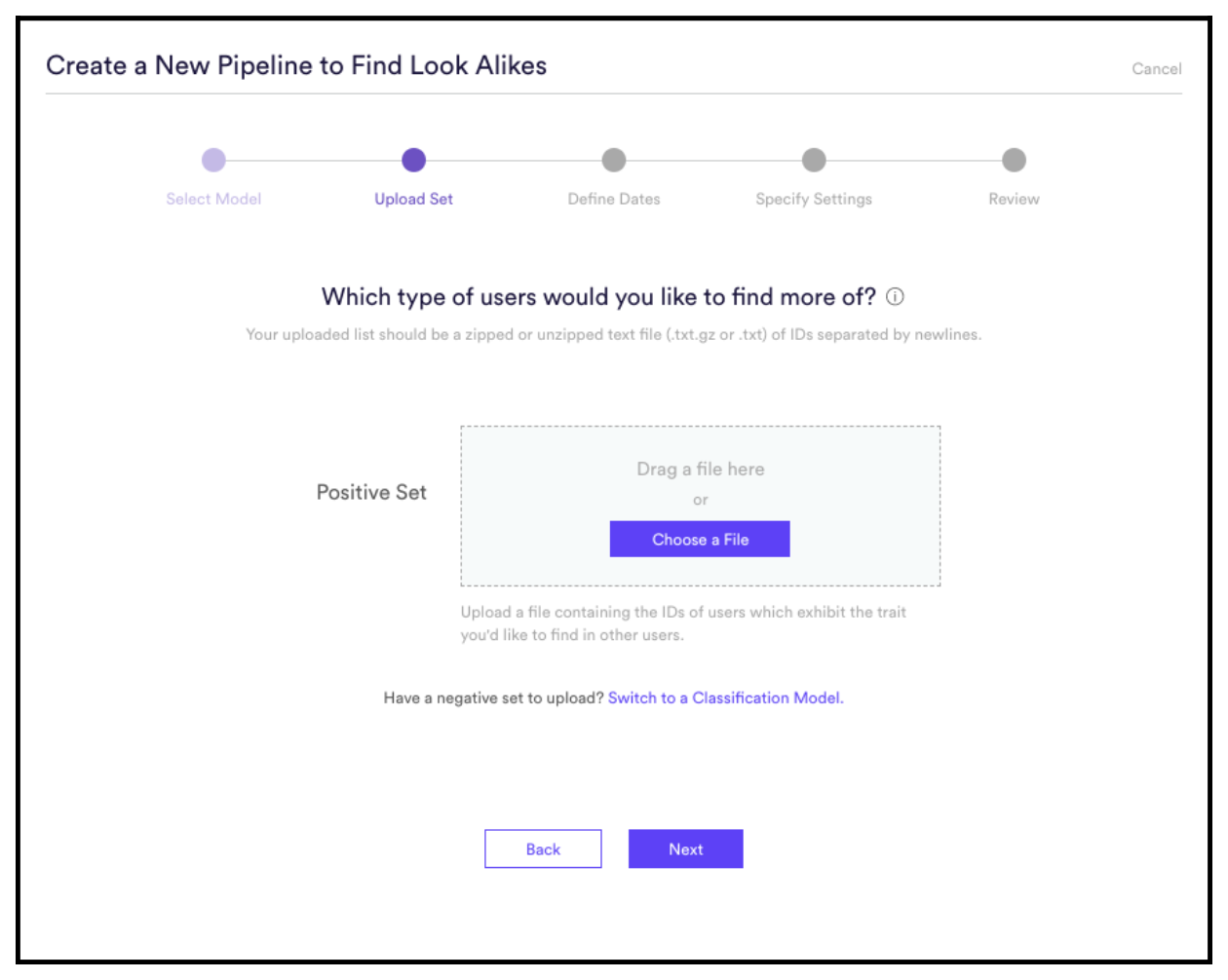 Example of Look Alike Model
Example of Look Alike Model
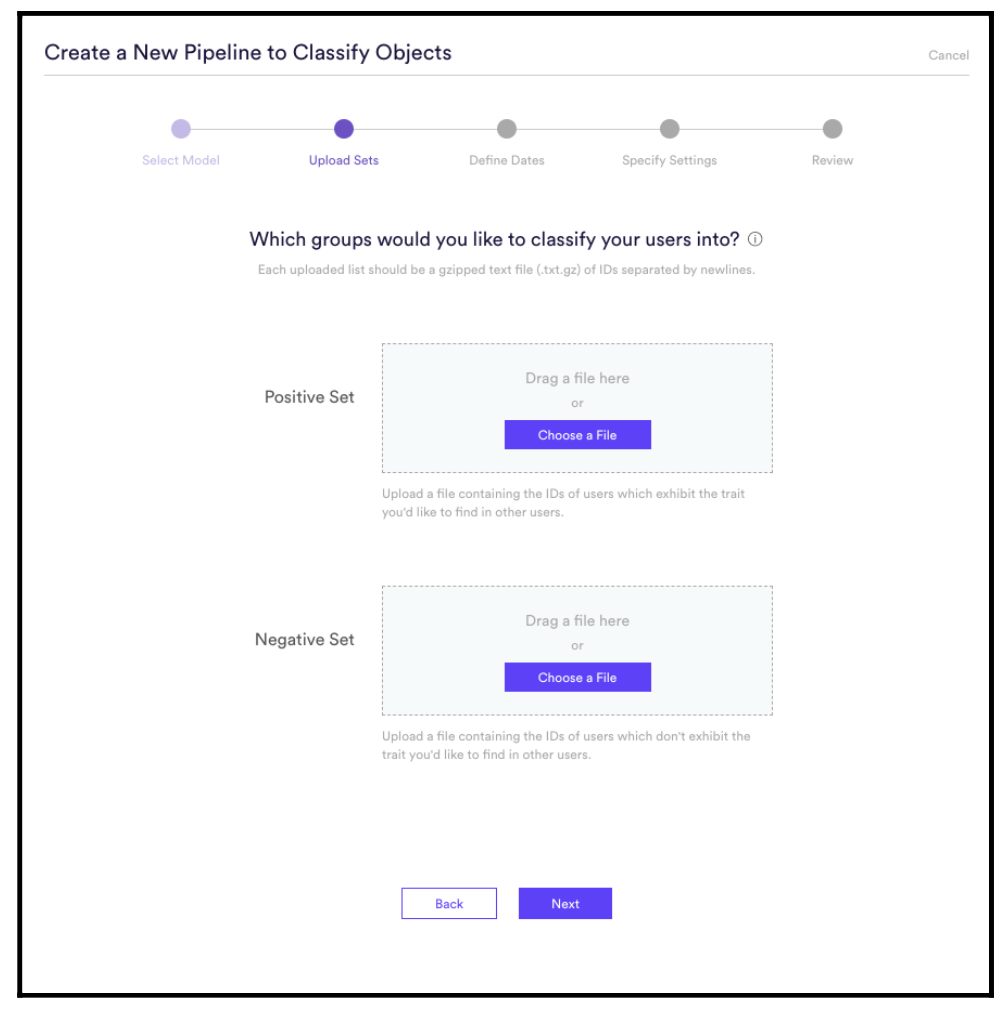 Example of Classification Model
Example of Classification Model
Vidora’s Unique Approach
Vidora’s platform takes a unique approach to these predictions. Instead of just looking at all the other static Customer Attribute values to predict the value for other customers, we look at all data including the behavioral actions taken by your customers to predict these values.
Vidora will aggregate all known Customer Attributes and Behavioral Actions taken by every customer, and use this data set as the basis for our predictions. Often customers of ours send in billions of behavioral events every month, which can make it hard to know what events lead to the best predictions.
This is where Vidora’s Automation makes this process seamless. With Machine Learning, the common saying of “Garbage in, Garbage Out” continues to ring true. To use Machine Learning terminology, this means the Features you create and give to your model are just as, if not more, important than the actual model you choose! Vidora will automatically turn this raw data into features, and will automatically test these features with dozens of different models. This takes the trial and error out of creating a predictive model, allowing you to go from raw data to prediction in no time.
Summary
With the advancement in Machine Learning, you no longer have to be content with incomplete data! Using Vidora’s Look Alike modeling, we can help make predictions based on raw behavioral data. This can allow you to create personalized experiences for a wider portion of your customers in a short time!
Want to know more? Contact us at info@vidora.com!


