
We continue to see broad adoption and excitement around real-time decisioning for experiences like next-best-action and next-best-offer. One of the key parameters for real-time decisioning is to decide what percentage of users will see an optimized experience, and which percentage of users will be used for learning by the algorithm.
With the latest Cortex feature, we enable our customers to specify the exact mix of users to optimize over and learn from. It’s all easy to do within a simple user interface. Our goal is to make it simple for our partners to experiment and control the real-time decisioning experiences for their users. This new feature has added significance for our partners whose revenue directly depends on decisioning. For commerce-like experiences, controlling the right mix of optimization and learning can have profound impacts on top-line revenue.
Below I’ll dive a bit more into the new controls you have access to as part of real-time decisioning.
Different types of decisioning cohorts –
There are three different types of cohorts you can specify within a decisioning project –
- Explore (the control cohort): Users are presented with decisions that are randomized. This cohort is used for learning.
- Exploit: Users are given decisions that are directly optimized by Cortex’s real-time machine learning decisioning technology
- Delegate (optional): Users are given decisions that are driven by logic provided by the business. We’ve seen that often businesses have existing heuristic logic they are using to optimize experiences. By specifying a delegate cohort, businesses can compare the performance of random and optimized (or “explore” and “exploit”) to their heuristic models.
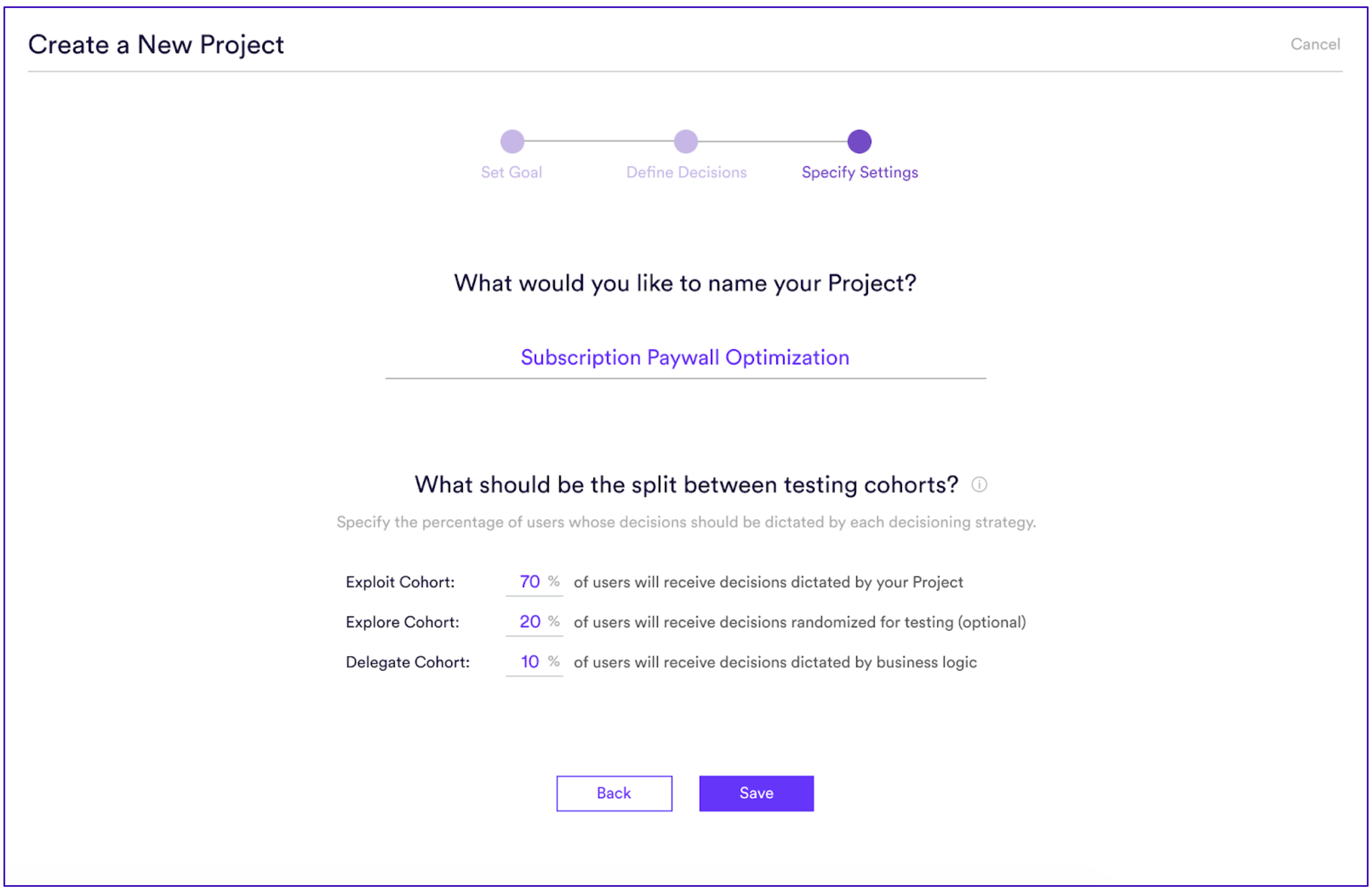
Decisioning in the Cortex UI. Example of a customized explore/exploit/delegate split in order to optimize for a subscription paywall
We want all our customers to have full control of their decisioning experiences. This new launch provides unique abilities for customers to specify the right mix of optimization and learning for their business. Contact us at info@vidora.com if you have any questions.


