
by Michael Firn (Product Manager at Vidora)
Data is everywhere, but most of it is messy, unstructured, and inconsistent. How can you unlock value from piles of raw information? The answer is feature engineering, and it’s what makes machine learning work.
 – Professor Pedro Domingos
– Professor Pedro Domingos
For all the buzz around data and algorithms, the difference between a good learner and a bad one usually comes down to which features are fed into the model. But selecting features is often the most difficult and imprecise part of the machine learning process. In this post, we explore why feature engineering is critical to model performance. We also examine how new techniques may pave the way for the next era of machine learning.
What is Feature Engineering?
Fundamentally, machine learning (ML) algorithms seek to learn relationships between inputs and outputs. Raw data is often a poor input — it holds valuable information, but that information is hidden from most algorithms until it’s been processed into a form more amenable to learning. Feature engineering is a critical component of this step.
Feature engineering is the process of transforming raw data to provide your algorithms with the most predictive inputs possible. Before seeing data, an algorithm knows nothing of the problem at hand. Humans, though, can inject prior knowledge into the equation. If, for example, we know from experience that changes in user activity are more predictive than raw activity itself, we can introduce this information. Given the infinite number of potential features, it’s often not computationally feasible for even the most sophisticated algorithms to do this on their own.
Let’s look at an example. Imagine that a media company is looking to predict which customers may become inactive. The company collects data on when each user reads an article, but an algorithm is unlikely to draw much insight from this raw data. Consider the following two users:
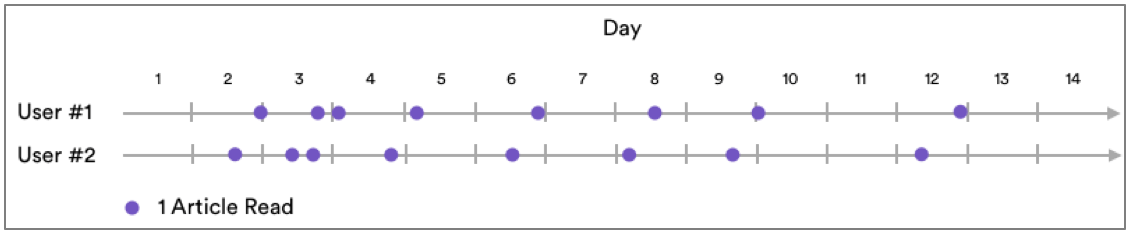
These users have displayed nearly identical patterns of article consumption. However, they are only offset by a few hours (perhaps they live in different time zones). Ideally, our model should assign them similar probabilities of churn.
Limitations
But most algorithms evaluate all features of each input in one step, and each input independently of the others. With only raw data at their disposal, these algorithms will learn only how activity at each instance relates to probability of churn. They won’t understand that reading an article at 12:00 PM marks essentially the same behavior as reading one at 12:15. Since the algorithms can’t see higher-level patterns, they treat the two users differently. This is because they never read at exactly the same time.
But all is not lost. Through feature engineering, we can provide a better representation of the data. When the algorithm compares our two users along the below features, they now look quite similar.
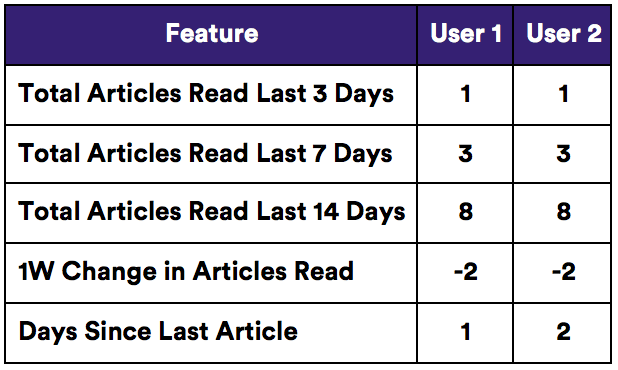
Why Does Feature Engineering Matter?
Features are the tools that your algorithm uses to make predictions. Your model is also only as good as your features are predictive. The algorithm will learn to emphasize important features. It will also ignore irrelevant ones. However, it can only work with what it’s given. If your inputs aren’t relevant indicators of what you’re looking to predict, they won’t reveal any patterns.
Not only do better features yield better results, they allow you accomplish more with less. With predictive features, the algorithm has less work to do in uncovering underlying relationships. This means you can get away with simpler models and less data without sacrificing performance.
Feature Engineering Today
Today, feature engineering is an art. Once you know how to present the data, science takes over — algorithms themselves are general-purpose and their methods are tried and true. Given the right data, the same algorithm used to diagnose disease can also predict customer purchase behavior and drive a car. Feature engineering, on the other hand, is domain-specific. Unsurprisingly, it often consumes the bulk of data scientists’ time.
The challenges they face are many and varied. Data scientists have an infinite pool of potential features to choose from, but cannot know a priori which ones will maximize predictive power. What’s more, predicting a new outcome (say our media company now wants to predict subscription) may require engineering an entirely new set of features. In theory throwing as many features as possible at your algorithm may allow it to learn the most predictive ones. But too much complexity puts a model at risk of overfitting, mistaking noise in the sample data for a true relationship.
With so many features to choose from and no rigorous methods of selection, data scientists are often forced to make educated guesses. But if they aren’t intimately familiar with with how your business operates, an uneducated guess may cost you performance.
Moving from Art to Science
For all its quantitative rigor, the success of ML often hinges on a subjective process. But the fact that machine learning’s secret ingredient is currently more art than science underscores just how much better ML models may still get. The biggest innovations over the coming years are likely to involve methods for processing data into a machine learning framework. In particular, some forms of deep learning (e.g. Convolutional Neural Networks and Recurrent Neural Networks) promise to automate feature engineering by having early layers of a neural network learn base features.
In today’s world of machine learning, it’s not enough to have data and algorithms — you need to present information in the right way. This is a difficult task, but luckily, much of the ML community’s collective brainpower is hard at work developing cutting-edge techniques. With the right innovation, they may open the door to a new level of predictive power in machine learning.


