
Any data scientist will tell you that data wrangling is most of the battle when it comes to Machine Learning. Your business may have a trove of data, but first you’ll have to process, clean, and engineer that data into features that an ML algorithm can understand. Traditionally, this has been a difficult and time-consuming process. Vidora’s Cortex makes it easy. Cortex is the only ML platform that automatically creates both event-based and attribute-based features from raw data, so that your business can get the most out of all its unique data sources.
Feature Engineering and ML
In its raw form, real-world data is too messy to feed directly into most Machine Learning algorithms. Turning unprocessed data into a usable form means first transforming it into features. This step is critical to any Machine Learning pipeline. As renowned AI researcher Andrew Ng puts it, “applied machine learning is basically feature engineering”.
In the enterprise business world, raw data typically comes in two forms: events and attributes. Events describe actions taken by your data points at particular points in time. Attributes describe characteristics or traits of those data points. Examples include –
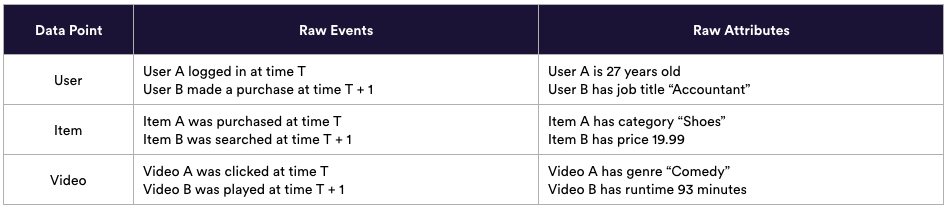
Cortex’s feature engineering pipeline can handle both forms at any scale – just upload a data source into Cortex or set up a direct integration of continuous data. Cortex will automatically transform this raw data into predictive features so that you can make complex ML predictions quickly and without hassle. You can also augment Cortex’s automatic feature engineering with custom features defined through a simple SQL-based UI.

More Data, Better Predictions
Your first-party data lets you create moats around your business, and Cortex makes it easy to leverage all your unique data sources into powerful ML models that can be deployed in a fraction of the time. Interested in using Cortex’s automatic feature engineering to get maximum value out of your ML efforts? Reach out to us at info@vidora.com to get started!


