Complex Feature Engineering with a Simple UI
Feature engineering for machine learning problems is often deemed a mysterious art. Yet, it remains one of the most important components to building a high performing machine learning pipeline. Feature engineering becomes even more difficult when considering that features are often built across billions of events that have to be organized and processed.
Vidora offers an automated solution that solves feature engineering for machine learning problems. Our key product, Cortex, also offers a powerful interface for manually creating complex features within a simple UI. This combination of automated and manual feature engineering offers businesses a framework to quickly produce high quality machine learning pipelines. Also, it offers the ability to augment those pipelines with business-specific logic.
In this post, we’ll walk you through how to build custom complex features for a variety of machine learning use cases and across billions of events.
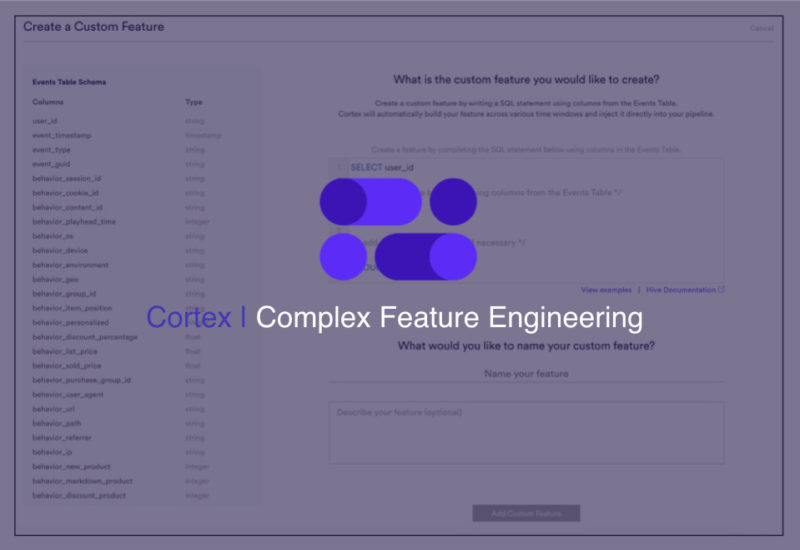
Cortex Custom Feature Engineering – The Interface
We designed our custom feature engineering solution to easily enable our partners to augment automatically generated features with manually specified features within a simple interface. Therefore, anyone with a basic knowledge of SQL can build custom features.
Some of the benefits our customers see include –
- Simple UI – Easy to understand interface powered by an underlying powerful SQL framework
- Scale – Engineer features over billions of events, Cortex takes care of organizing the events within the simple interface
- Easy Integration – apply engineered features across multiple pipelines with a few clicks
- Evaluation – compare the performance of various automatically generated and manually generated features
Finance – Predicting Loan Default
One common use case is to predict whether a customer is likely to default on a loan. Typically, the raw data needed to predict loan default includes:
- Event data corresponding to the customers payments such as is the customer paying on time and the amount of each payment
- Event data corresponding to a customers interactions with the business including online activity and support activity
- Metadata associated with the customer including financial information on the customer
- Metadata on the loan including loan amount and number of remaining payments
The data above is provided to Cortex through either a Sandbox account (learn more about Sandbox accounts here) or by leveraging Cortex APIs. Also, Cortex will automatically generate features based on the event and metadata above provided above.
However, businesses are able to augment this data through custom feature engineering and build features unique to their business. Examples of possible engineered features include –
- Is the customer becoming more delinquent in payments over time?
- Are the customers increasingly visiting a particular section of the website with information on loan defaults?
- Are the percentage of negative customer support calls increasing or decreasing over time?
Commerce – Predicting Purchase Propensity
A common use case for commerce companies is predicting whether a user is likely to buy an item in the next few days. Data typically includes –
- Event data associated with in-store purchasing behavior associated with user including what the user is buying and how much they are spending
- Event data associated with online behavior including shopping cart interactions, category interactions, and online purchases
- Metadata associated with users including demographic information on users
Automatically generated features typically include the most important features for generating strong performance on purchase propensity problems. In addition, more complex features include –
- The percentage of morning purchases increasing over the last 30 days (might be indicative of a change in a customer’s employment status)
- Is the customer increasingly purchasing items in a particular category over the last 90 days?
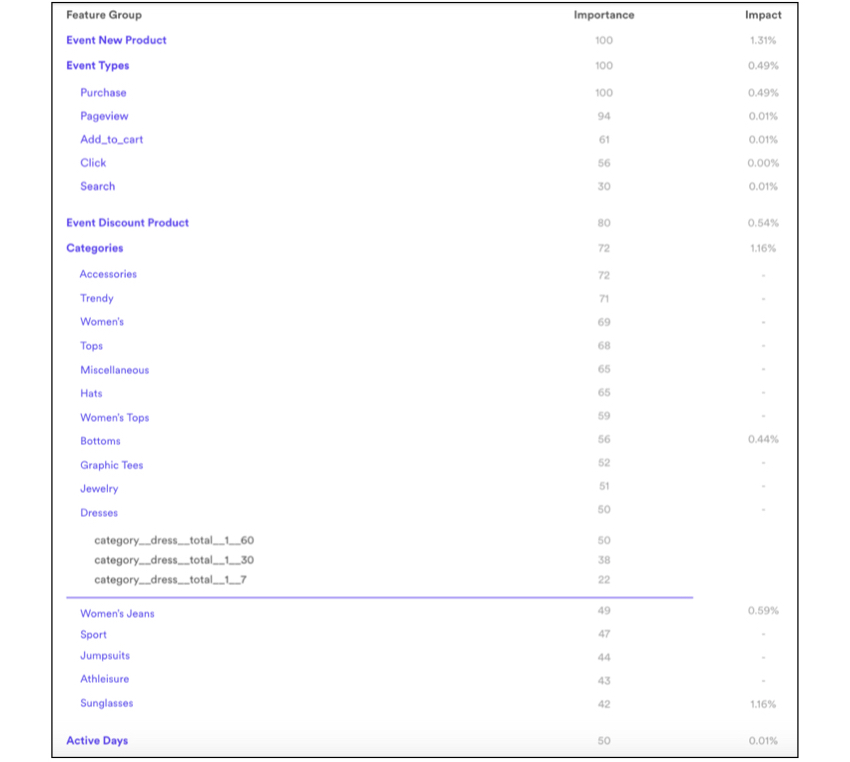
Customizing Features Enables Great Machine Learning Pipelines
In summary, automatic feature generation can get you 90% of the way to high performing machine learning pipelines with little effort. However, Cortex offers you the ability to easily augment automatically generated features with complex custom features in a simple interface. We’ve spent a good deal of time thinking through how best to provide a powerful interface for our partners to create their own custom features across billions of data points. We are looking forward to seeing the features you build!
Some more useful links –
Lastly, here a couple quotes to leave you with on feature engineering –
 — Xavier Conort, “Q&A with Xavier Conort”
— Xavier Conort, “Q&A with Xavier Conort”

— Pedro Domingos, “A Few Useful Things to Know about Machine Learning”


