
Propensity models are an increasingly important machine learning tool for marketers and product managers. Propensity models are used for such broad ranging tasks as predicting churn, predicting the likelihood of purchase, and predicting when to send a marketing campaign. After building a propensity model it is natural to want to evaluate the performance of the model. Evaluating model performance may seem like a straightforward task, but in this post we will explore some of the nuances around evaluating propensity model performance and suggest three methods for assessing how well your propensity model is actually performing.
Propensity Models
Propensity models in marketing predict the likelihood of a user doing a particular action. That action could be churning, buying a product, or clicking on an email. A good propensity model will provide an accurate measurement of how likely a user is to perform any given task.
But how do we define how good a particular model is? We will explore three techniques for determining the quality of your propensity model –
- Model Training Performance
- Future Model Performance
- Historical Future Model Performance
As a side note, in this post we are considering propensity models that predict a users activity in the future. In other words, there is a temporal component in the propensity model.
Model Performance – Training and Test Sets
In order to evaluate the types of propensity models we are considering in this post, we will always divide the data into “Training Data” and “Testing Data”.
| Training Data | Data used to find the best propensity model. |
| Testing Data | Data used to evaluate the performance of the best propensity model |
Why divide the data into training and test sets? When evaluating a propensity model we want to understand how well that model will generalize to new, unseen data. The idea being we want to find the best model using the training data and then test the performance of the model using a distinct set of data that it has never seen before. This is one common technique to help avoid overfitting a model.
The test data should look as similar as possible to the data the model will see in the real world.
Below we explore several different ways to define a training and test set.
Propensity Model Performance Evaluation – Model Training Performance
The standard way to evaluate a machine learning model is to divide your data randomly into a training and test set without any other considerations.
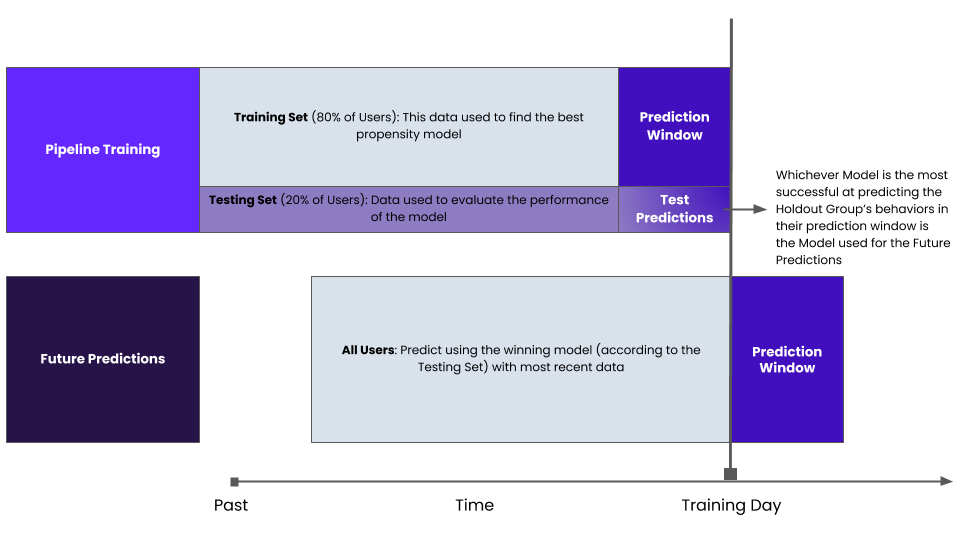
Note, importantly, that the training and test set are from the same time-frame. In other words, we are implicitly assuming that the best way to estimate real-world performance is to choose a training data from the same time period as the training data.
Vidora’s no code machine learning platform Cortex shows the performance of a model in the following way where AUC, Accuracy, Precision, and Recall are all ways of evaluating how well the model generalized to the test set of data.
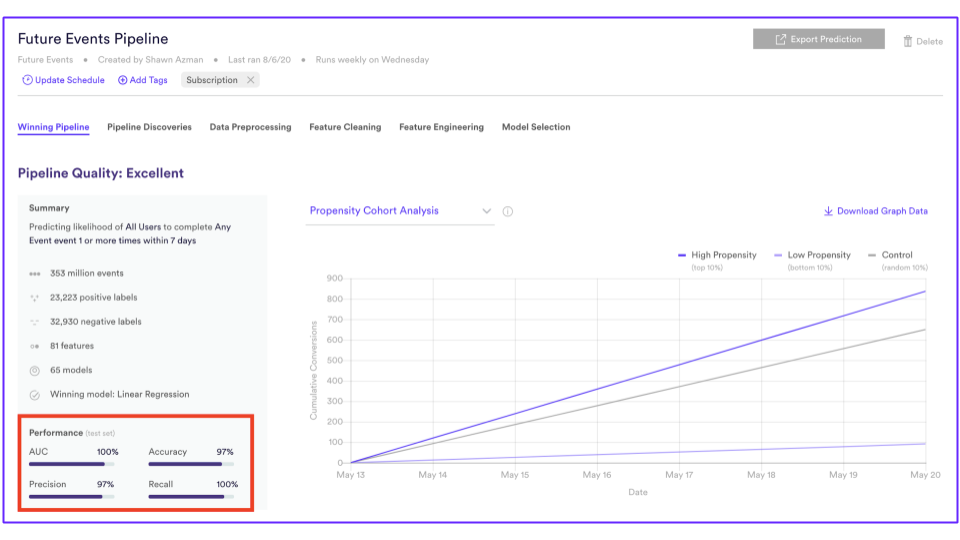
Propensity Model Performance Evaluation – Future Model Performance
Now let’s consider another way to evaluate the performance of a propensity model that takes into account a temporal component.
One obvious way to evaluate a model is to build the model taking into account data up to a specific day, and then test the model using data that appears after that day.
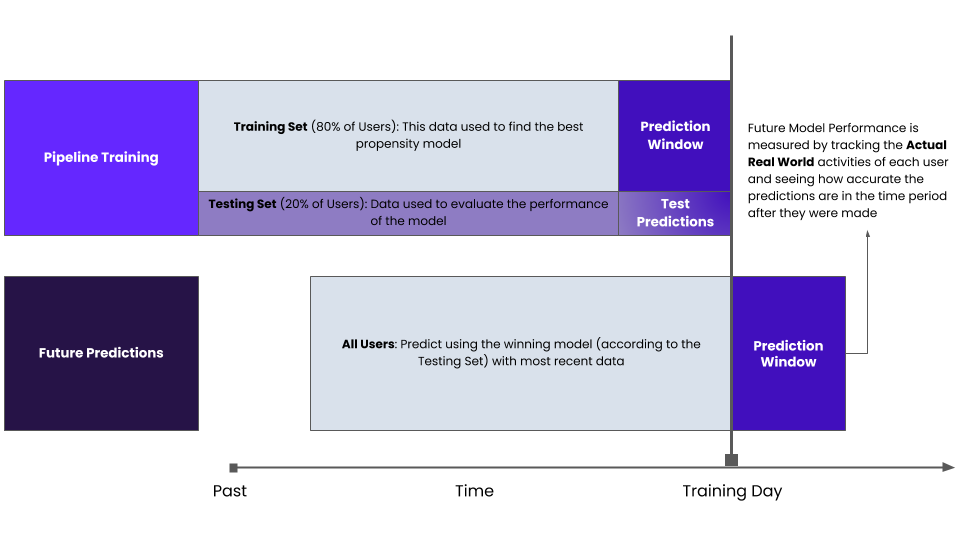
This method of evaluating model performance has some nice properties including that it is evaluating the future performance of the model explicitly. Cortex also provides the Future Model Performance evaluation out of the box as you can see in the image below. Cortex automatically evaluated the performance of the model on different cohorts of users based on the data it receives.
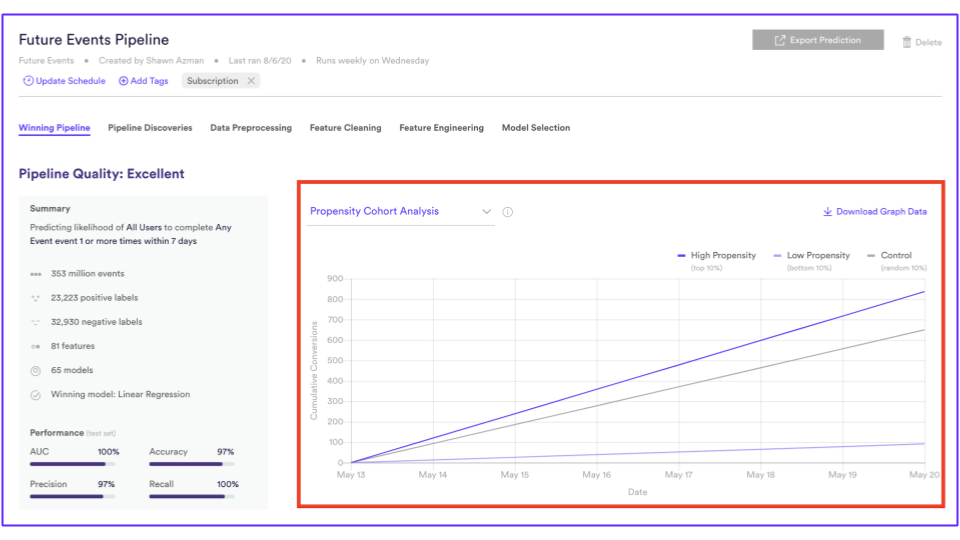
Future model performance is a great way to evaluate your propensity model performance. However, it has one significant downside. What if we want to train a model today and push the model live today? How do we evaluate future model performance today?
Propensity Model Performance Evaluation – Historical Future Model Performance
This brings us to the 3rd type of propensity model evaluation. In this evaluation, as with Future Model Performance, we will train the model using data up to a specific date and test it on data after that date. But in this case, the date we use to divide the train and test set will be in the past.
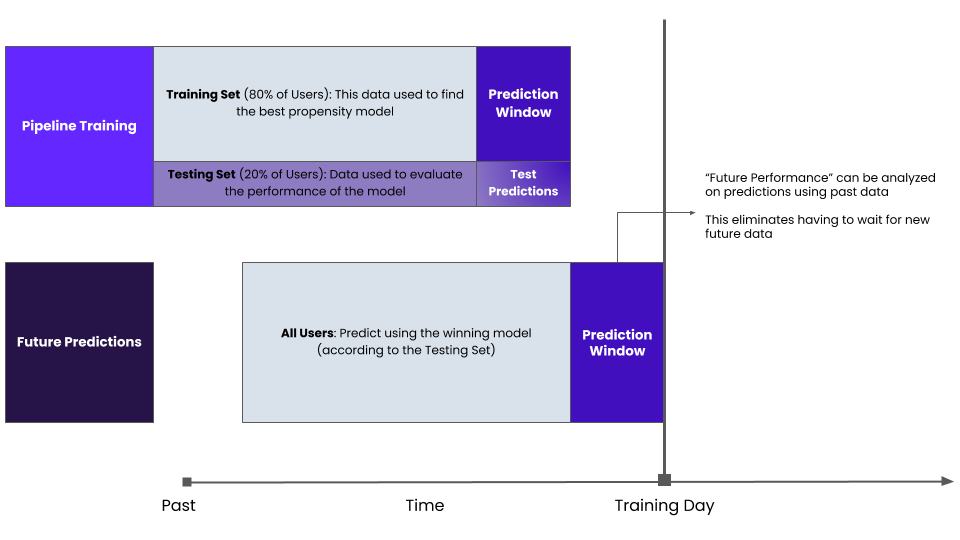
Training on a historical date and testing on historical data after that date allows us to evaluate a model today in the context of Future Model Performance without needing to wait for future data to become available.
Cortex also provides the ability to train and test on historical data by specifying a training date in the past.
Which Propensity Model Evaluation Method Should I Use?
The right evaluation method will depend on the exact use case and it’s difficult to know which method will be the best for a particular problem. However, we’ve built Cortex to make it easy for you to understand model performance across each of these evaluation methods meaning that you can assess performance in a variety of ways.
If you are interested in learning more about propensity model evaluation or Cortex please reach out to us at partners@vidora.com.


