
Are your Machine Learning efforts slowed down by data wrangling? Vidora’s Machine Learning (ML) Pipeline technology automates aspects of data wrangling including pre-processing, feature cleaning, and feature engineering, allowing you to quickly build out operational Machine Learning models.
Get Started Now
Getting up and running with automated data wrangling and ML Pipeline creation is easy. Here are the 3 simple steps to get you started –
-
Upload Your Data
Cortex intelligently processes, cleans, and engineers features from raw event data. Events describe actions associated with each of your data points. Examples of events include –
- Customer makes a purchase through your e-commerce platform
- House is listed for sale on your real estate listings website
- IoT device sends a status update
To import your event data into Cortex, simply drag and drop a CSV file in the UI. Cortex automatically cleans and transforms this raw data into features which can be used to make ML predictions. You can also augment Cortex’s automated capabilities by defining custom features through a SQL-based UI.
Below is a sample of the hundreds of features which Cortex might automatically engineer using events collected online from an eCommerce platform. A file containing events like these can be uploaded directly into Cortex (click to download a sample file), where they’ll be transformed into features like those listed below.
- Total # of purchase events last 7 days
- % of clicks with category = shoes last 14 days
- Days since last activity
- Number of unique devices last 30 days
-
Build ML Pipelines
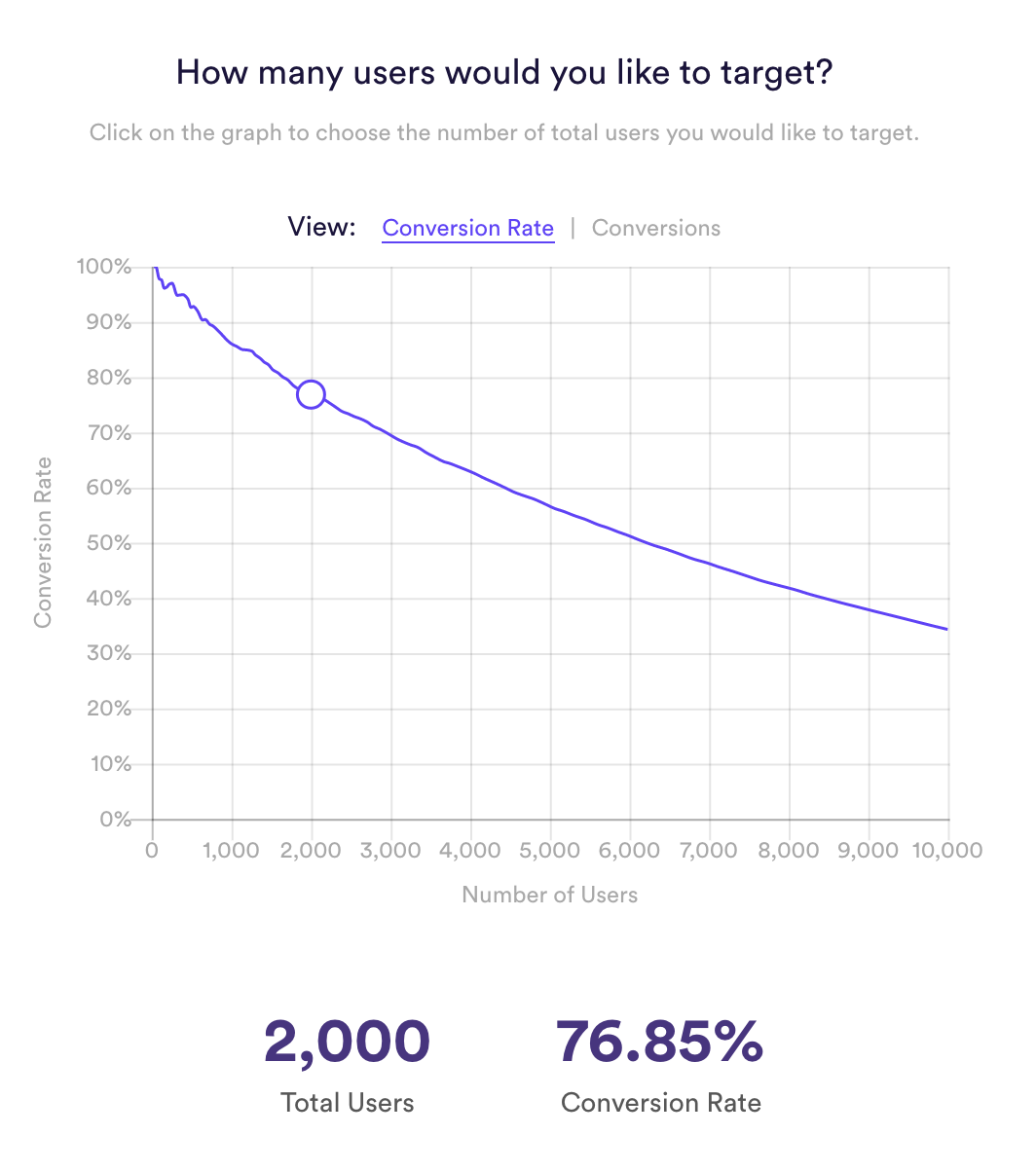
Once the file is processed, Cortex allows you to build ML pipelines within a simple interface. Cortex offers many of the most common types of pipelines you will encounter in your business.
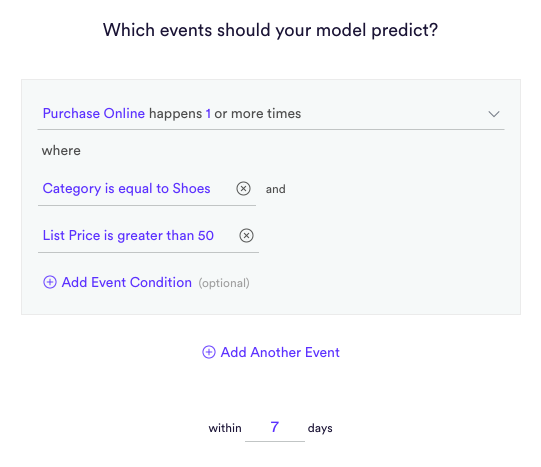
-
Export Predictions
Once the pipeline is finished processing, download the predictive results in a CSV file so that they can be put to use by your business.
It’s that simple – drag a CSV file into Cortex, select a target for your ML pipeline, and export results.
Sending Continuous Event Data
If you would like Cortex to build pipelines based on continuous live data that can be configured as well using our APIs or sending data on an ongoing basis to Google Cloud, AWS, or MSFT Azure.
Questions?
Interested in learning more? Email us at info@vidora.com.


