Look-Alike modeling is a powerful method for expanding an existing dataset with known attributes. Increasingly, businesses are turning to Machine Learning (ML) in order to build these Look-Alike models in sophisticated ways. Use cases include –
- Expanding a set of known users (i.e. known “high net-worth users”, “CEOs”, “in the market for a mortgage”, etc.)
- Finding more houses similar to a set of existing houses
- Finding more commerce items similar to a known set of commerce items
Facebook offers a well-known framework for expanding audiences across the Facebook ecosystem. In this post, we explore how your own 1st party data can be similarly used in Look-Alike models. We also highlight how Cortex empowers anyone to build Look-Alike models with just a few clicks. For more background, here is a previous post on Look-Alike modeling from Vidora. This Quora discussion on the subject may also provide helpful info.
What is 1st Party Data?
First party data is information you collect directly from your audience, customers, or business. By contrast, 2nd and 3rd party data is information you obtain from an outside source (see this Hubspot post describing the various types of data). Examples of 1st party data include:
- Data from behaviors or actions collected across your website, app, or marketing campaigns
- Subscription data
- Data in your CRM including demographic or survey data
Look-Alike Modeling and Semi-Supervised Learning
In Machine Learning terms, Look-Alike modeling is a form of semi-supervised learning. Semi-supervised learning is unique in that only positive labels are specified, versus supervised problems which require examples of both positive and negative labels from which to learn. When you build a Look-Alike model, you only have access to the positive label set that you’d like to expand — users, houses, commerce items, or otherwise — so your problem fits into a semi-supervised framework.
Building Look-Alike Pipelines in Cortex
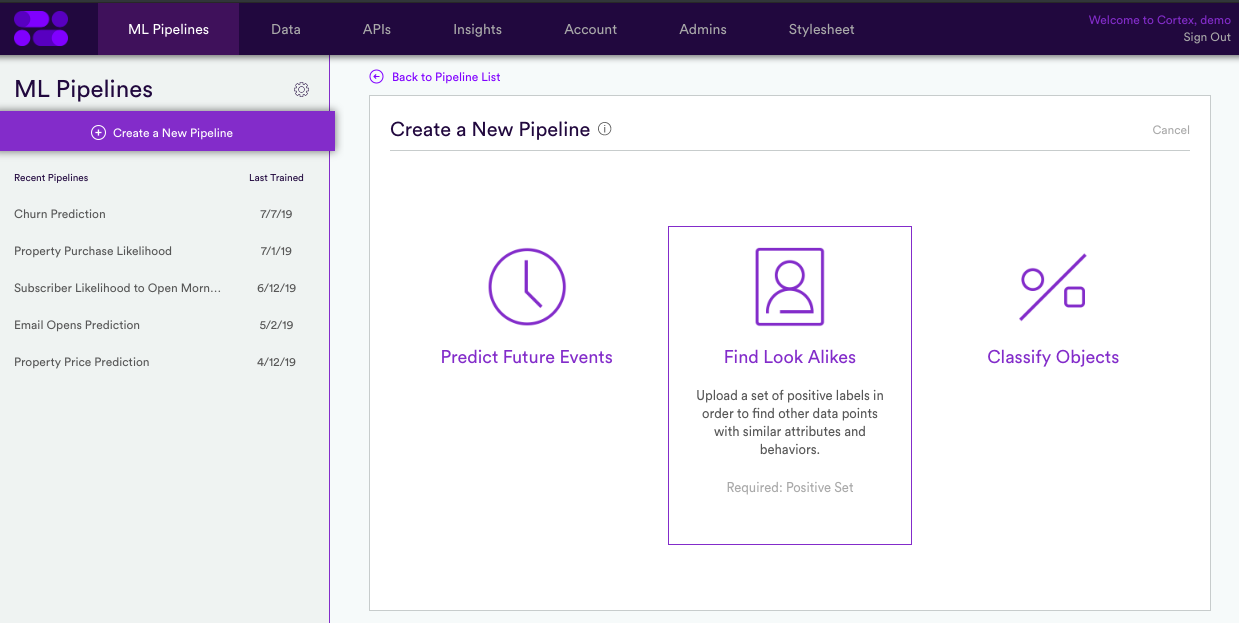
Cortex offers a self-service platform for building Look-Alike models quickly and easily. Cortex approaches Machine Learning by building ML Pipelines which turn raw data into predictions. These pipeline can also process large-scale data in real-time and on an ongoing basis.
Getting started with Cortex is simple. First, specify a directory containing ongoing events and metadata. You can also send these events directly to Cortex via our APIs. Once you’ve done this, upload a set of positive labels into Cortex to begin training your pipeline. You can then access your pipeline’s predictions by exporting a list of IDs ranked by their similarity to your positive labels.
It’s that easy. Just 4-5 clicks and then you can be up and running with Look-Alike models built using your 1st party data.
Learn More
To learn more about Vidora Cortex and how to build Look-Alike models with 1st party data, email us at partners@vidora.com and ask for a demo or trial.


