
Big data, automation, and AI play increasingly important roles in helping businesses better understand and predict user behaviors. This post explores the statistical concepts of “precision” and “recall” as it relates to one of the most critical metrics for any business – user churn.
Machine Learning – Some Basics
Let’s start with some basics on machine learning. In machine learning an algorithm uses a set of “training” data. We then evaluate the performance of the algorithm using a set of “test” data. Training and test data contain both input features and an output result.
For Vidora’s churn prediction algorithms, the input features are user behaviors. These include what searches the user made, or what pages the user visited. In general, any user behavior can be used as an input feature. The output is whether or not the user churned. The algorithm is trained with a huge set of input data and behaviors (potentially up to thousands), and the output is whether or not the user churned. The job of the algorithm is to “learn” from the training what patterns of behaviors result in user churning. The performance of the algorithm is then evaluated on the “test” data. If the algorithm works well, it will be able to generalize what it learned from the training data to the test data.
A natural question arises of how accurate the churn prediction algorithm is on the test data? That’s where the concepts of precision and recall come into play.
Let’s Start With A Thought Experiment: Red Balls & Blue Balls
What are “precision” and “recall”, and how can that help reduce user churn? Precision and recall are terms used to describe how accurate a machine learning algorithms is – in the case of churn, they describe how accurate the churn prediction algorithm is. Let’s consider a simple thought experiment with blue and red balls:
There is a ball pit filled with red balls and blue balls. You have a machine whose task is to identify and separate out the red balls into a bag.
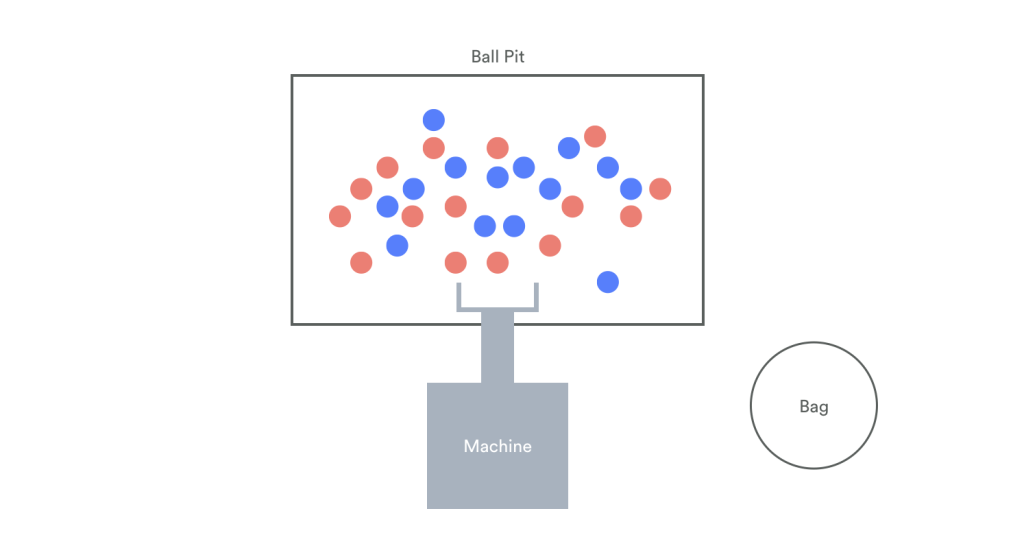
The machine finishes its task, and we now have to see how well it completed the task. To assess how good our machine is, we’ll need to test its precision and its recall. But before we get there, let’s set up the framework for our assessment using a confusion matrix:
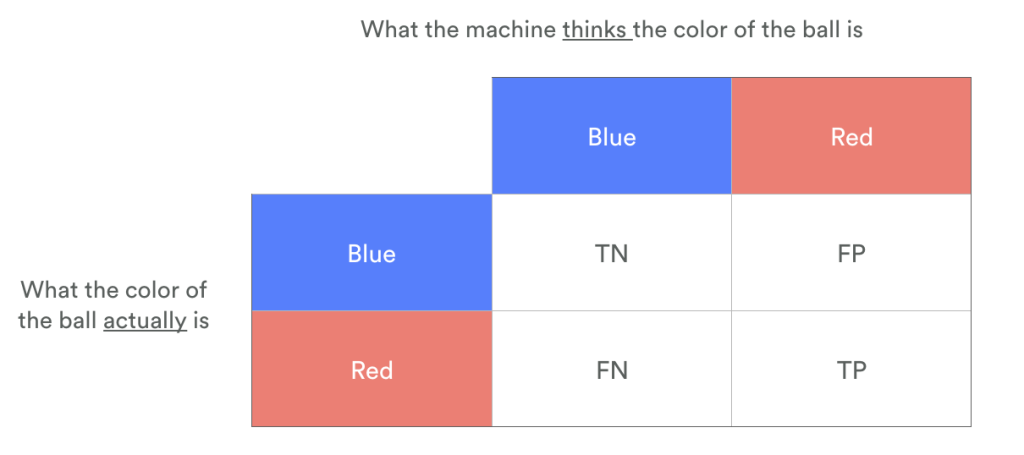
As we look at the balls which the machine has separated out from the pit, there are four possible ways to define each ball:
- TN = True Negative: These are the blue balls that the machine correctly identified as blue, and therefore left in the pit
- FN = False Negative: These are the red balls that the machine incorrectly thought were blue – these red balls are still in the pit
- FP = False Positive: These are the blue balls that the machine incorrectly thought were red and separated from the pit, even though it wasn’t supposed to
- TP = True Positive: These are the red balls that the machine rightly identified as red, and pulled out of the pit
So now that the machine has finished its task (see the diagram below), and we know how to define each ball, let’s look at precision and recall:
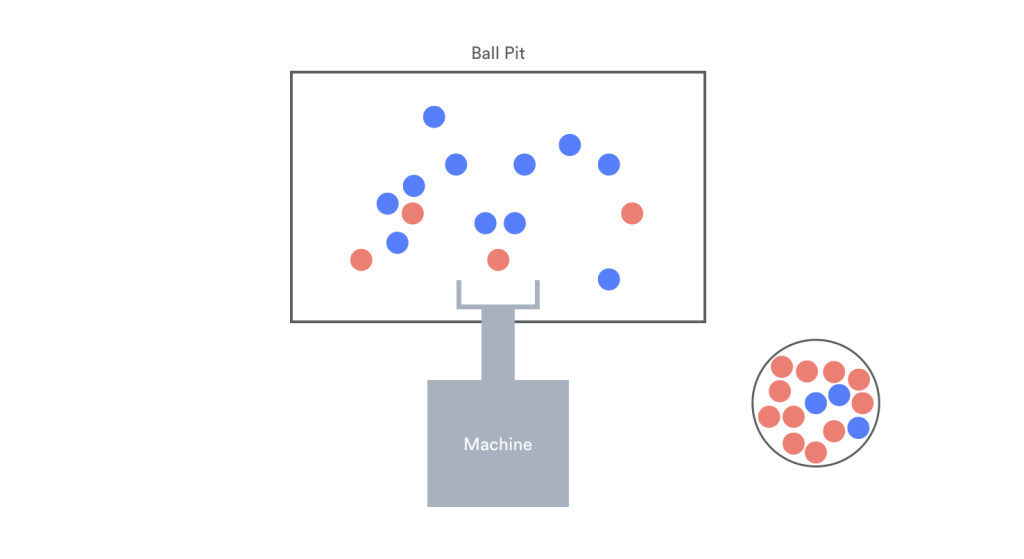
Precision
Precision, in this case, is defined by the proportion of red balls in the bag against all the balls in the bag – i.e. what proportion of red balls did the machine correctly identify out of all the balls that it thought were red?
In general, precision is given by the formula (TP) / (TP + FP)
Recall
For this thought experiment, recall is defined by the proportion of red balls that are in the bag against all of the red balls, both in the bag and still in the pit – i.e. what proportion of red balls did the machine pull out, out of all the red balls we had to begin with?
In general, recall is given by the formula (TP) / (TP + FN)
Precision, Recall & Churn
Now let’s consider precision and recall as they relate to churn.
- Precision – Of all the users that the algorithm predicts will churn, how many of them do actually churn?
- Recall – What percentage of users that end up churning does the algorithm successfully find?
As you can see, both precision and recall are important for evaluating the performance of a churn prediction algorithm.
Precision & Recall Are Inversely Related
It might have become obvious that precision and churn are inversely related. For instance, if an algorithm predicts that every single user will churn, it would have perfect recall. But clearly, not every user will churn from your business – and your algorithm’s precision would end up being very low, and it wouldn’t be useful for your business.
On the other hand, if that algorithm only predicts that one user will churn (for instance if the user is completely inactive for months), it will have perfect precision. But clearly, this will mean that a lot of users who end up churning will not be identified, and you’ll have very low recall – not very useful either.
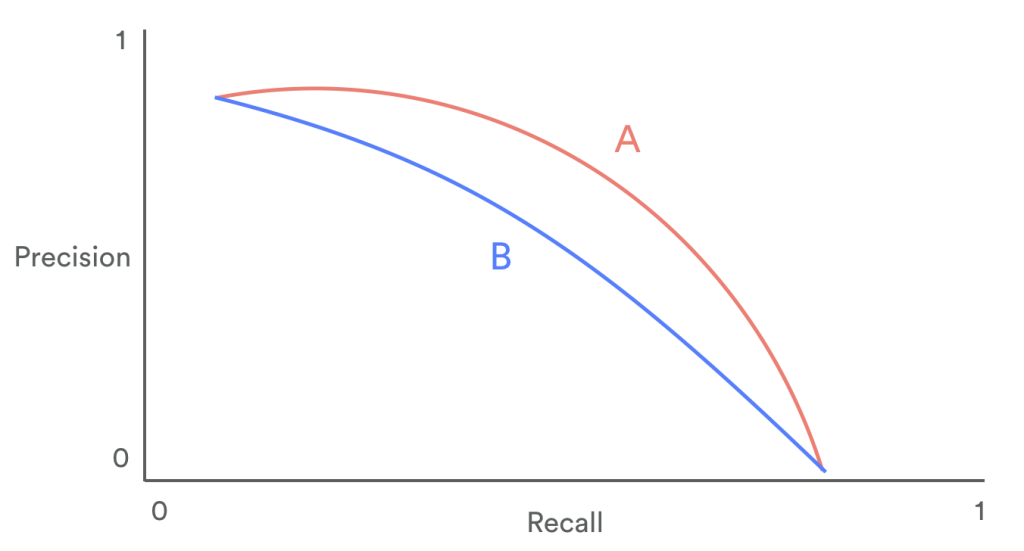
The plot above shows how precision and recall are typically related to one another for two different algorithms, “A” and “B”. Note that as the precision increases (move up and to the left) the recall decreases for both algorithm “A” and “B”. And vice versa. If the recall is very high (lower right) the precision decreases. In this case algorithm “A” is performing better than “B” based on the curves shown.
Tuning Precision & Recall To Minimize Churn
No algorithm will predict churn with 100% accuracy. As a result, there will always be a tradeoff between precision and churn.
Consider a re-engagement email campaign which says something like “We noticed you may be leaving us. Please don’t!” You’d likely want to ensure that the precision for this email was high. In other words, you would want to minimize the number of happy users who see this email, and instead have this email almost exclusively hit users in danger of churning.
On the other hand, consider an email that you want to send more broadly to your user base – maybe an offer to receive $5 of the next purchase. You’d be less concerned with users who are not in danger of churning receiving this marketing message. Ideally, though, you would want anyone who might churn to see the email. In this case, you would want your recall to be higher than your precision.
You as the marketer can decide what works best for your business. Vidora’s algorithms can be adapted to ensure the precision and recall that works best for your business. Machine learning is a powerful tool to help you make the best decisions – start reducing churn with Vidora today!
Here are some other resources to learn a bit more about precision and recall –
- Quora – What is the best way to understand the terms “precision” and “recall”?
- PDF explaining the concept of Precision and Recall from Creighton University



