
Cortex offers a variety of tools to enable your teams to increase key business metrics. When it comes to increasing short term metrics like clicks or conversions, one great machine learning pipeline to explore is Cortex Category Recommendations.
Here we will show you not only how to build a great machine learning pipeline to increase engagement, but also how to monitor both pipeline performance and the infrastructure surrounding that pipeline to ensure the pipeline is working at its best.
Step 1 – Define your Machine Learning Model
First, you will want to specify what we want to recommend. In the screenshot below we are specifying which of several “Discount Offers” we want to offer a user.
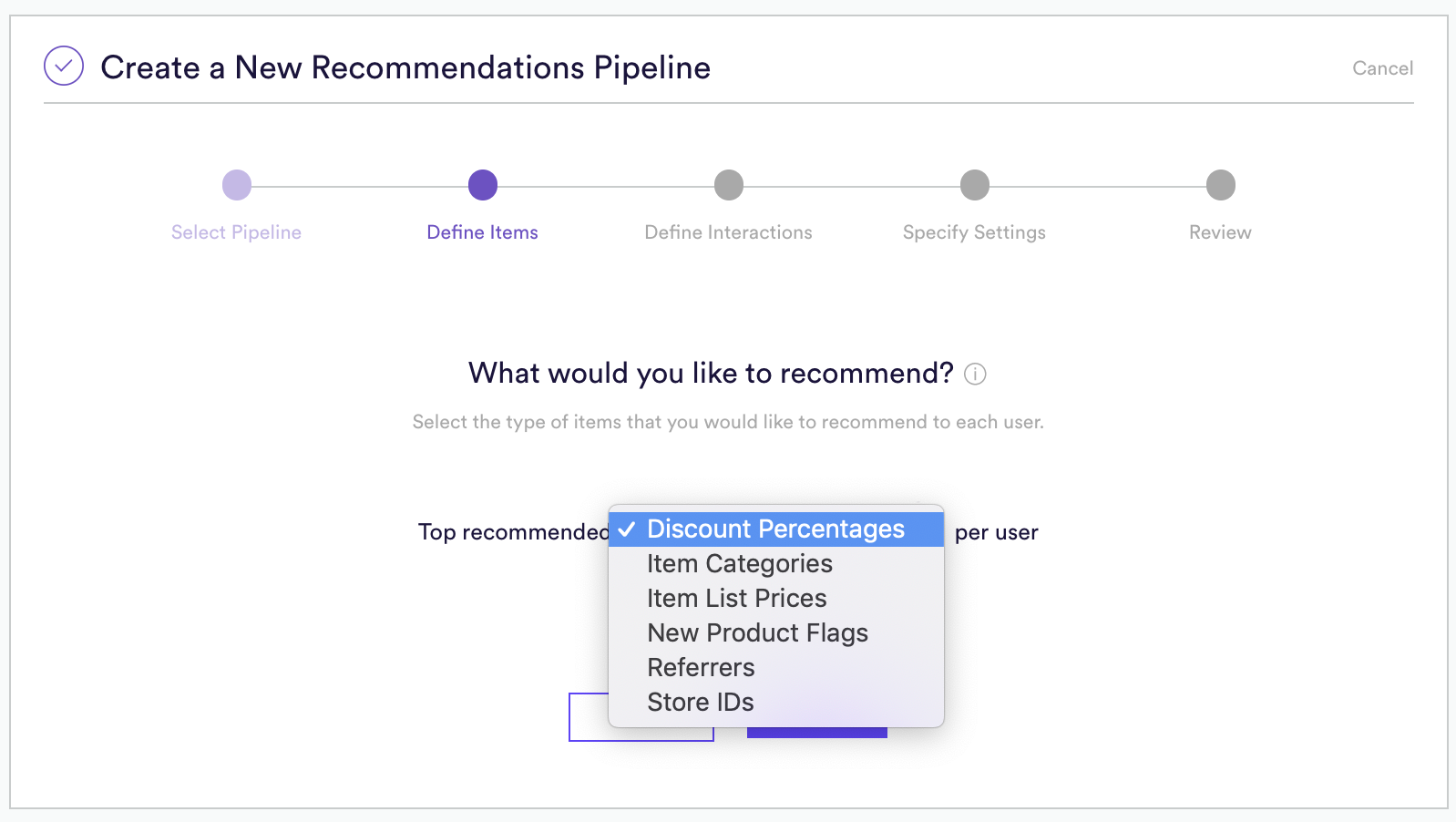
Almost any element which has multiple categories associated with it is a good category for recommendations. Here are some examples of what we could recommend and optimize on a per user basis –
- What Offer to recommend
- What Category of Content to recommend
- What Author to recommend
- Etc, etc, etc!
Second, you will want to specify the optimization goal. What outcome are you optimizing for? In this case we are selecting “Add To Cart”. So this recommendation pipeline would suggest the best “Discount Offer” to give each user in order to maximize “Add To Cart” actions.
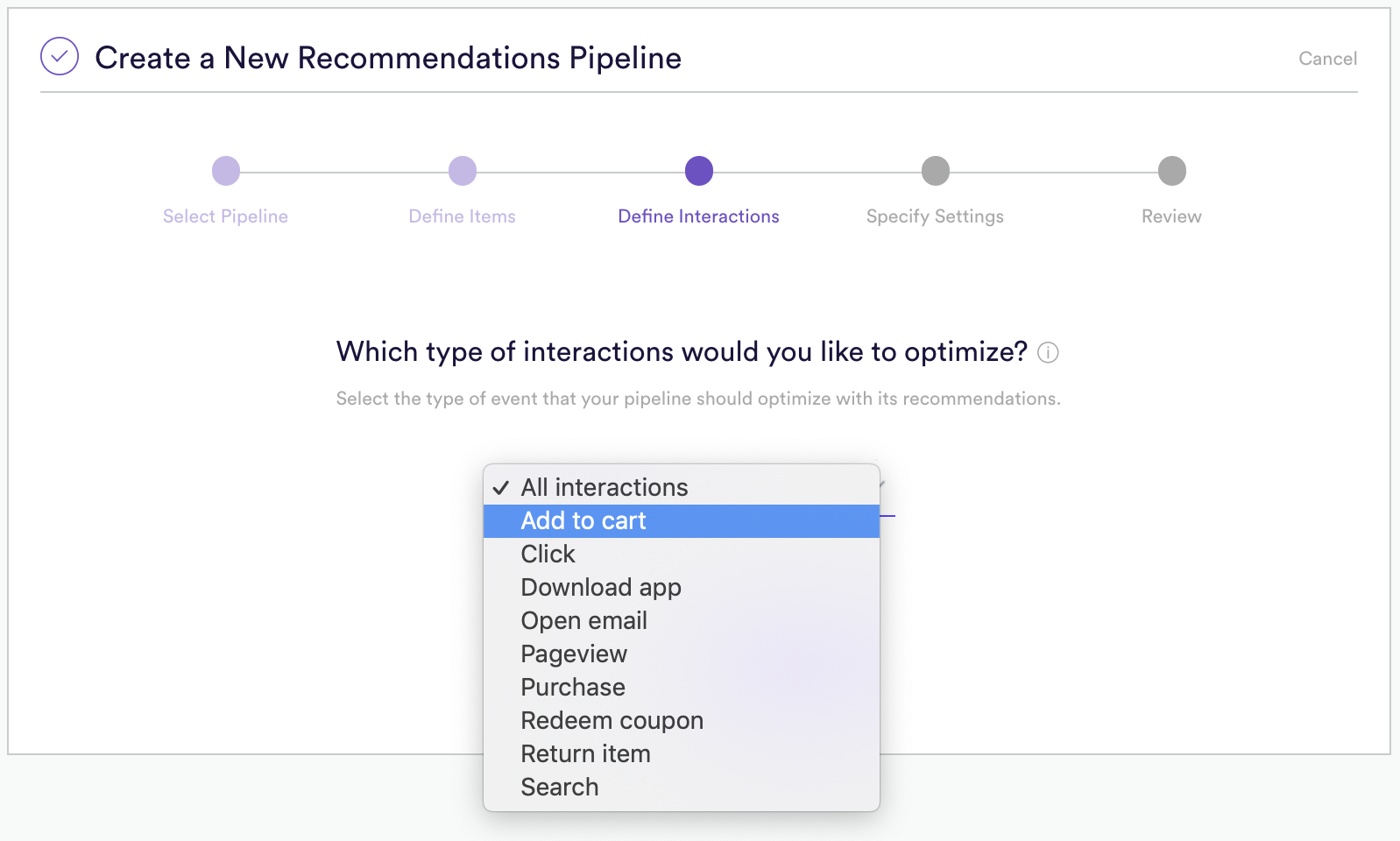
Third, there is no third! Specifying what you want to optimize for and what the algorithm should choose from is all you need to do!
Step 2 – Validate Performance
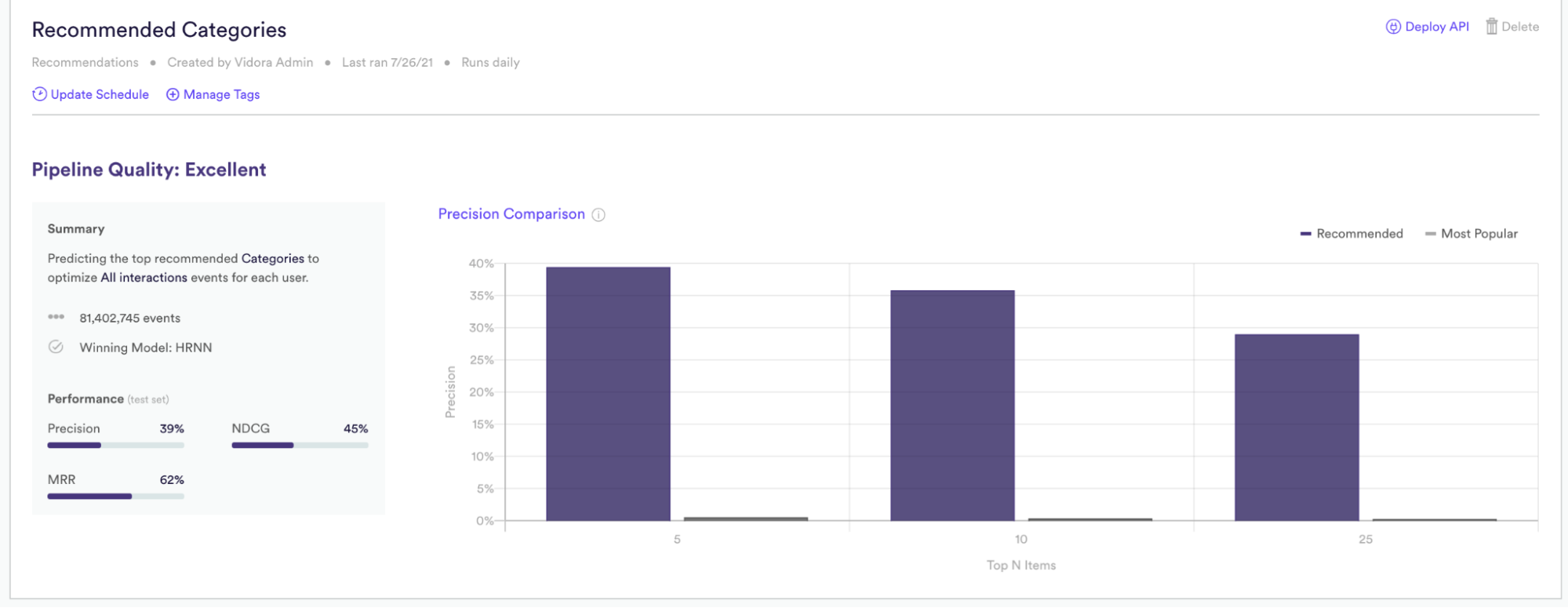
The next step involves ensuring the algorithm is improving results for your business. Cortex automatically validates the performance of your machine learning pipeline by comparing the 1:1 recommendation algorithm to an algorithm which would pick the “most popular” item. Cortex also compares the performance if 5, 10, or 25 items were shown to a user to help guide UI decisions.
Below is a snapshot of Cortex comparing the 1:1 personalized algorithm with the most popular algorithm. In this case the personalized algorithm is far outperforming most popular meaning that this business will see a large increase in user engagement as a result of using this machine learning pipeline. Note that these comparisons between the recommendation algorithms and the most popular algorithm are generated after each training run of your algorithm. These comparisons are a great way to show stakeholders the performance of the algorithm and the impact of the machine learning pipeline on your business.
Step 3 – Monitor the Model Infrastructure
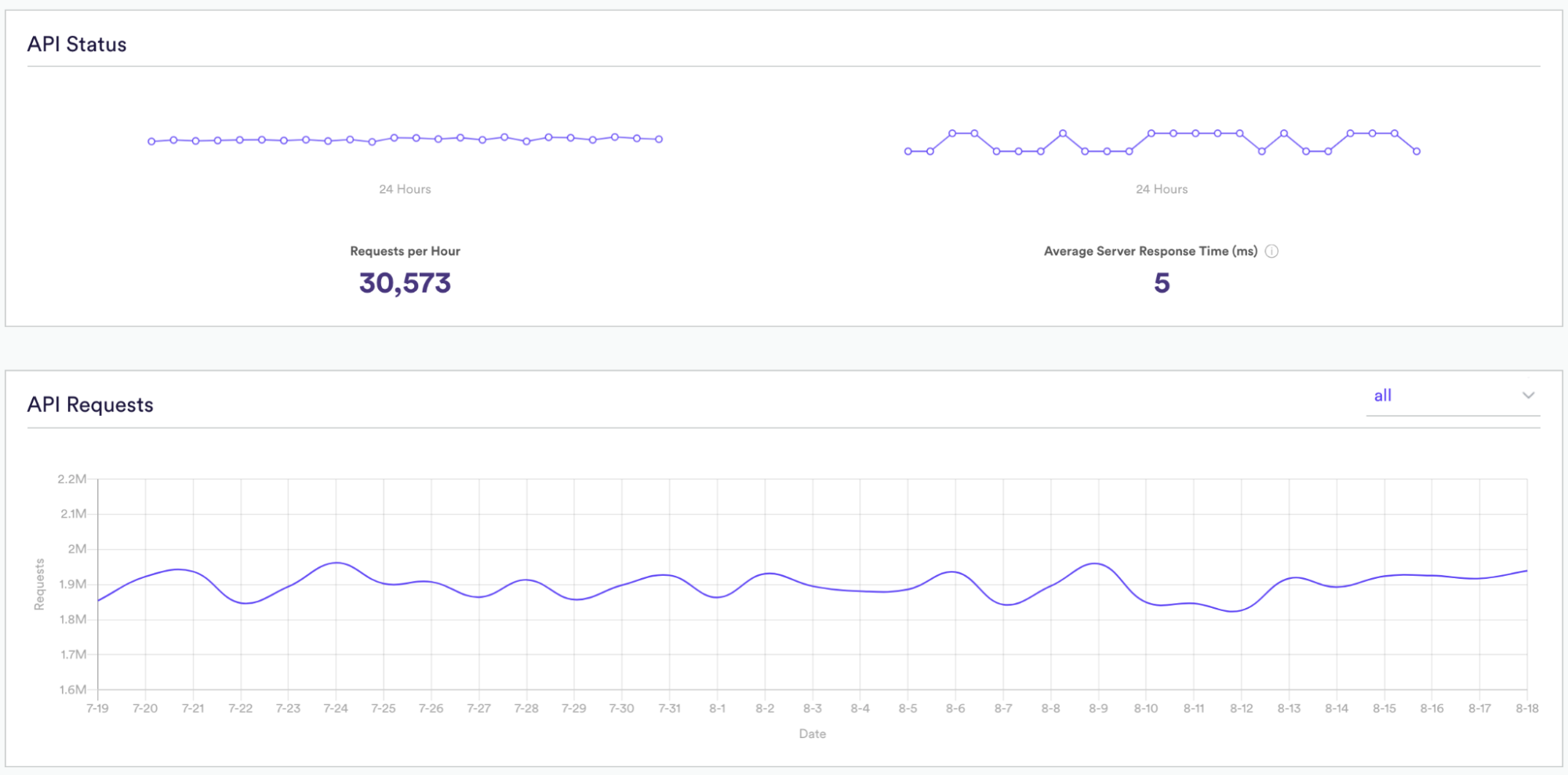
The last step is to ensure your team has the proper tools to monitor the model infrastructure. Often our partners choose to deploy low-latency APIs to enable a fast decision on which personalized item to show a user. Below we illustrate some of the monitoring available in Cortex for the APIs including –
- Requests per Hour
- Average API Latency (in this case 5ms)
- Change in API call cadence over time
Summary
Machine learning can dramatically increase some of your key engagement metrics like clicks, conversions, and purchases. But deploying machine learning pipelines requires not only an easy way to build the pipeline but also tools to monitor the pipeline performance. In addition, the infrastructure around live pipelines should be monitored to ensure that results are being delivered quickly. Cortex should offer your team a holistic framework for building and monitoring your pipelines. Combining all these areas together enables your team to build new machine learning-powered experiences with confidence!


