Watch our ongoing series on how automated machine learning can accelerate personalization strategies and ROI for enterprise marketers and product managers.
Converting Anonymous Users to Registered Users [Part 2]
With less reliable data for anonymous visitors in a competitive environment, it’s vital that business teams are able to operate nimbly, be data-driven, and harness machine learning to punch above their weight class.
In the AI 2.0 marketplace, the winners will be separated from the losers by their ability to effectively adopt machine learning and AI applications without the near-unlimited resources of the FAANGs.
Vidora’s Cortex can be the bridge that automates otherwise complex and manual machine learning processes and powers data science controlled and directed by business teams.
In Part 1, we walked through the ability of Cortex to automate the entire process of ingesting, processing, and learning from existing data – all in a matter of just weeks.
In Part 2 below, we’ll run through the customization options within the interface that allow business teams to run predictions on almost any data segment, and talk about Cortex’s ability to learn and identify the most important data features for accurate machine learning predictions.

Contact
Contact us using the form below to learn more about Vidora. We’re excited to hear from you!
—Read the full interview below—
—Competitive Advantage: Customized Attributes and Events Segmentation—
Aaron Huang:
Let’s go ahead and set up this pipeline prediction here. One of the interesting things about what you just mentioned in terms of this use case is that there are different segmentation behaviors based off of attributes and behaviors that happened before the registration event, and after the registration event. So let’s kind of talk about how this pipeline gets set up, because it’s a very interesting use case for some of the flexibility in this system.
Shawn Azman:
Yeah, definitely. The really great thing about Cortex is, all of the predictions that you’re going to make are going to be made specifically off the data that you send into the platform. So if you want to predict an action in the future, any action that you’re currently tracking can be used to power that. So I think it’s really important to start with, what kind of data are we actually capturing and sending over to Cortex. So I have a demo account pulled up here, and we’re looking at the data that I’ve currently sent in just to give an example of the flavor of data that we’re going to use to power any prediction, but here specifically, looking at users who are going to register. And again, it really exists around these two data types, events and user attributes. And this is just one example.
Shawn Azman:
So we can track an event. Specifically, say that the user here, just User ID 1, is subscribing at a specific time. Well, we can also add additional context to that event. The location from which it occurred, the device. Also if you have different subscription tiers, that would absolutely be the place to say that as well. If you have say, bronze, silver, gold tiers, you could send that over as an attribute so that we could predict not only that somebody’s going to subscribe, but particularly which subscription are they going to choose. So there’s always more information that you can send over to either create different predictions, or to make more accurate predictions than the ones that we’re already doing.
Shawn Azman:
But a really crucial part of this prediction is to understand the current state of the users when they’re performing these actions. So as you can see here in this example dataset that I pulled up, we do have a user detail which is user’s subscription status. Specifically here, this is a non-subscriber. So this may be obvious that this is a non-subscriber who’s going to take the action to subscribe so that they can transition to being a subscriber or a member, but this is really important. Because what we want to do in the pipeline that we’re about to create is learn the usage patterns of specifically these non-subscribers. We want to know what patterns of behavior or usage are going to lead these non-subscribers to eventually take that action, and register, and become a subscriber. And so this is just one example. We’re going to get tons of these different events coming from all of your different users, be they members or nonmembers, and we’re going to use all of that to train the pipeline.
Shawn Azman:
And so I did just want to start here and talk about just kind of the data that we’re capturing. But now we can actually go into creating the prediction. And so within Cortex, that’s going to be a new pipeline, specifically predicting a future event. Because what we’re doing is we’re taking all of these usage patterns and saying for each one of our users, what’s the likelihood that they’ll take a specific action in the future? Here, it’s going to be a subscription. So the first thing that we have to do is save what we’re trying to predict. And as we were just looking at the data that’s coming into Cortex, that exact same data is going to be what’s shown here for your predictions. And so as you start to track different behaviors for these users, that will be the events and behaviors that you use for predictions.
Shawn Azman:
So here, specifically what we want to know is which of these users are going to take the action, which is subscribe. For this data set, we only have one subscription tier, but if we did have additional subscription tiers we would be able to classify that here as well. Maybe those who are going to subscribe to a gold tier for example. And then the question is, in what timeframe do we want this action to occur? Maybe we run a weekly email campaign, in which we really want to know, are these users going to take this action within the next week? Or maybe this is a monthly newsletter in which it’s more important for us to know this on a monthly cadence. To the platform, you just give that information and we’ll be able to configure the prediction specific to what you need. Here, we’ll just stick with a month. Who is most likely to subscribe over the next month.
Shawn Azman:
And here is where we get into the user attributes. So the prediction is going to be based off an event. We’re trying to predict that the user’s going to take an event in the future. Here, we say for whom are we trying to make this prediction? Because right now, we’re going to say for any user that we’re currently tracking, what’s the likelihood of subscribe? But we would assume that there’s a large portion of our users who are already subscribers for whom this prediction doesn’t make any sense. And so rather, what we want to do is specify that this prediction should only be made for those users who are non-subscribers. And so you can see here, we have different segments of these users. We have those who are non-subscribers, those who are currently subscribed, those who have churned. So you can send over any attribute that you want into this platform. And maybe for this prediction, we actually want to know, are churn users going to resubscribe? So this would essentially say anybody who is not currently subscribed, what’s the probability you will within the next 30 days? Or rather, maybe this is a new user acquisition campaign, and really we’re just focused on acquiring net new users to the platform, in which case non-subscribers would be the way to go.
—‘Featurizing’ Data for Machine Learning—
Aaron Huang:
I know in the past when we mentioned analytics systems that we used to do to make these inferences, essentially what one would do was take a list of all the events, and essentially run a correlation analysis and try to make an educated guess on what certain events were more likely or less likely to trigger registration. Do I, as a user in this system, have to basically hypothesize and select a specific event that is related to a registration event, or do I basically pipe in all of the events, and you guys are actually telling me the events or the attributes that are most correlated or most likely?
Shawn Azman (23:42):
Yeah, you hit on maybe the hardest part of all machine learning, which is all the trial and error and all the guesswork that goes into creating an accurate prediction. If you’re a data scientist, there’s certain steps that you need to go through before you could even try to run a prediction. And I think a lot of the things that you’re talking about right now, we’ve already talked about just getting the data, aggregating it, processing it, cleaning it. But let’s assume that we’re already there. We already have all the data that we need. Now we need to say, okay, what’s going to be the most predictive for our pipeline? We call this featurizing your data. Essentially, taking all of this raw data that you have, and formatting it specifically for our machine learning pipeline. But if you’re a website that captures a ton of different events, it’s actually not a best practice to simply send all of those events over to your model to learn from. This is often what we call over fitting, and computers are super good at finding patterns, insomuch that they may actually find patterns that don’t exist in real life. That’s what we typically refer to as over fitting.
Shawn Azman (24:41):
So your point is very well taken, in that we need to find not just all of the features within our data, we need to find the right features within our data. And this is really where Cortex comes into play, because oftentimes this is as I mentioned before, trial and error, guess and check work, where we’ll sort of guess and see, if I choose this feature versus if I choose that feature. Cortex takes all that guesswork out of the equation, and will automatically do that for you, each of those steps. And what I mean by that is we’ll automatically create the features for you from your raw data, and then we’ll automatically apply those features to multiple machine learning models, and will only choose the combination of features and model that give you the highest prediction.
Shawn Azman (25:20):
So essentially, we’re doing all the trial and error and guesswork for you, so that all you need to be concerned about is what business question are you trying to answer, and Cortex will take care of all of the automation of getting your raw data to that function.
Aaron Huang (25:31):
Got you.
Shawn Azman (25:35):
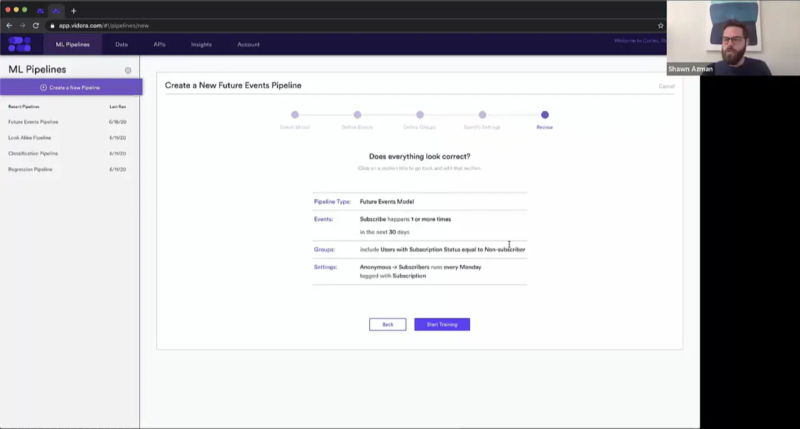
And so to really quickly sort of finish off this pipeline, we’re just going to set a few settings and then start training. So here, we’re trying to find anonymous users converting to subscribers. And again, continuous learning is an integral part of machine learning. So maybe we only need this prediction once for maybe a marketing blast that we’re going to do, but more often than that, especially with anonymous users to subscribers, this is not going to be a one-time prediction. This is a prediction we’re going to need to have on continuously over time. So maybe I’ll set this pipeline up to recur every Monday, so that every week we have fresh new predictions for all of our users to use within the product. We’ll tag this with subscription.
Shawn Azman (26:16):
And that’s really all that we need to do, and we can really quickly check our work. So we have a future events pipeline that’s trying to predict a user will subscribe one more time in the next 30 days. And we only need to make this prediction for those users that are non-subscribers. And we’re going to re-run this every Monday.


