Machine learning has the potential to dramatically augment the productivity of marketers across enterprise organizations. In this blog post we uncover yet another machine learning secret to help marketers be even more successful with machine learning.
Machine Learning Models – Training Data
Machine learning models learn from past data and use that information to predict future behaviors. One of the most important and most overlooked tasks when building a machine learning model is specifying which data to use for training. Specifying the wrong data can result in poor model performance and make it more difficult to evaluate model performance.
Example Model : Predicting who will Purchase on Mobile
Let’s use an example to illustrate why selecting the right training set is important. Consider a commerce site which is interested in predicting who will purchase an item within a native mobile app. The model will use past mobile purchase events to predict who will purchase on mobile in the future. What training set of past data should we use?
Many marketers might be tempted to use all their data which would include users who never had any activity on a mobile device. If we use all the data we will be including users in the training who have never downloaded the mobile app experience. The model, when learning the purchase prediction, will then be forced to consider non-app users. By considering additional, non-relevant users, the model may perform worse on the predictions for the actual mobile users.
A better solution would be to ask the model to learn only on mobile users since after all these are the only users who would ever purchase on a mobile app. This will almost always result in a more specific and higher accuracy model.
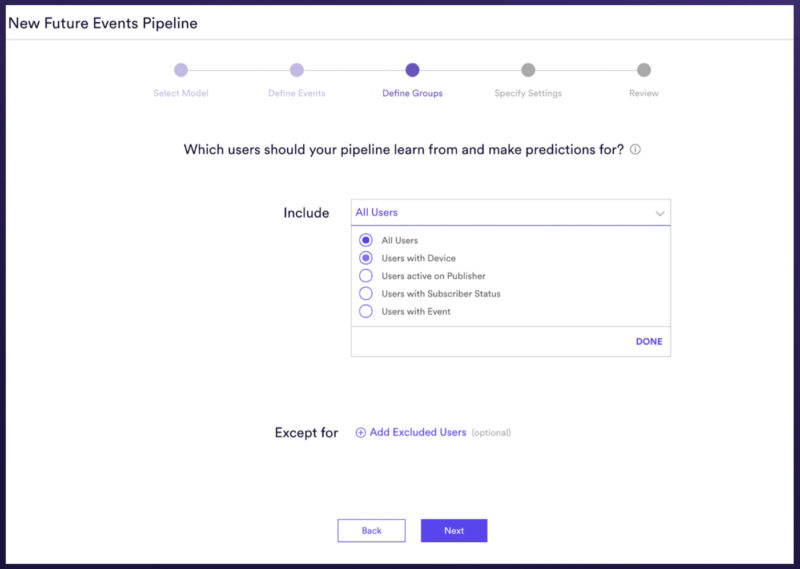
Example of the Cortex UI and a user specifying to train a model using only mobile app data.
Evaluating Model Performance
In addition to increasing model performance, specifying the right set of users to train with and make predictions can also make it easier to evaluate your model performance.
Consider again the above scenario in which we can train either (1) on all users or (2) only users who have downloaded the mobile app. Let’s say we want to target the top 10,000 users who are most likely to purchase. In scenario (1), where we included all the users, we would be including users who do have never downloaded the mobile experience and therefore would never purchase on mobile. Scenario (2), where we only train and predict on mobile users would generate a more appropriate set of users.
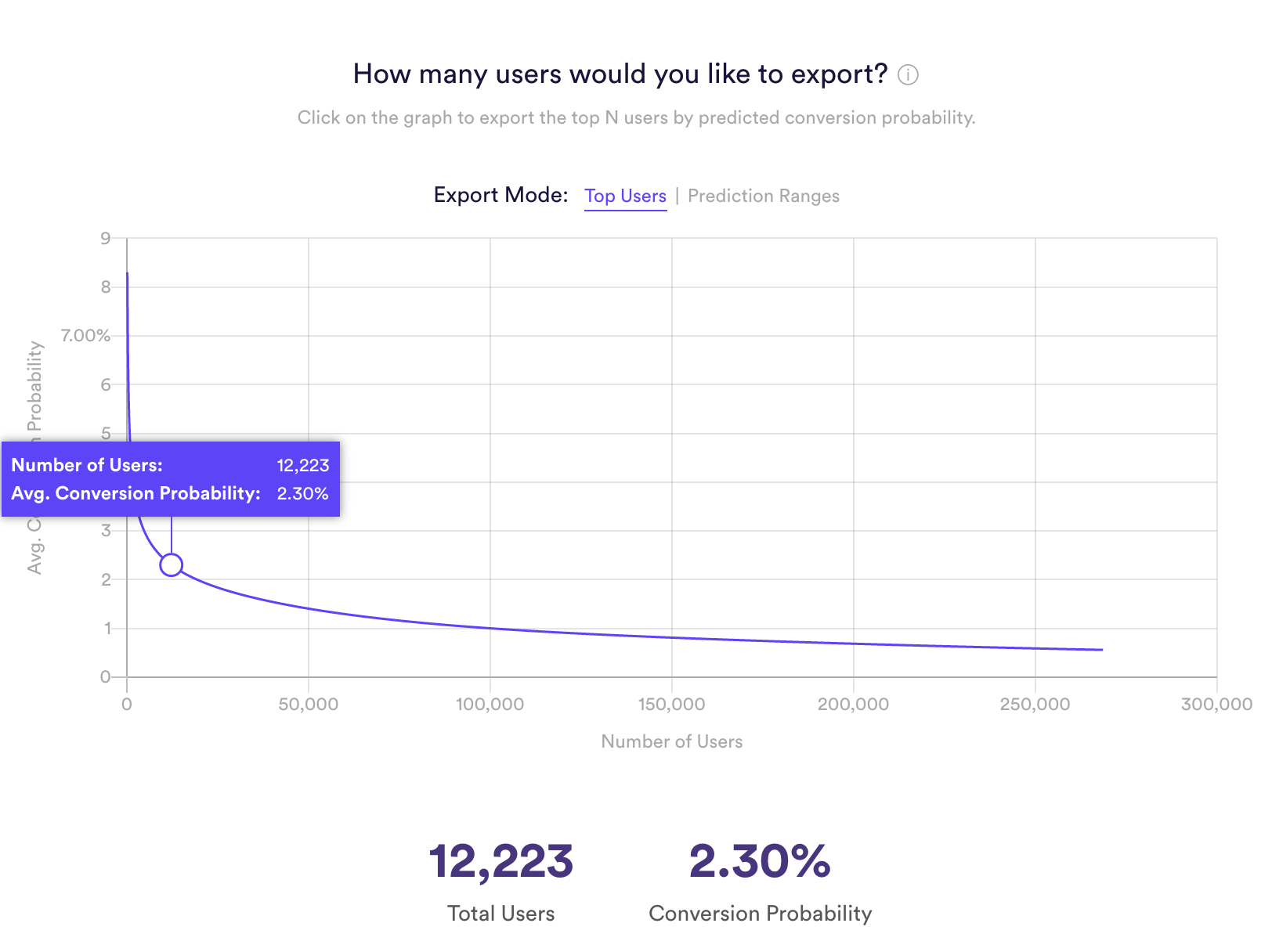
Screenshot from Cortex in which a user is selecting the top 12,000 users to target with a Future Events Model.
Cortex – Specifying Arbitrary Training Cohorts
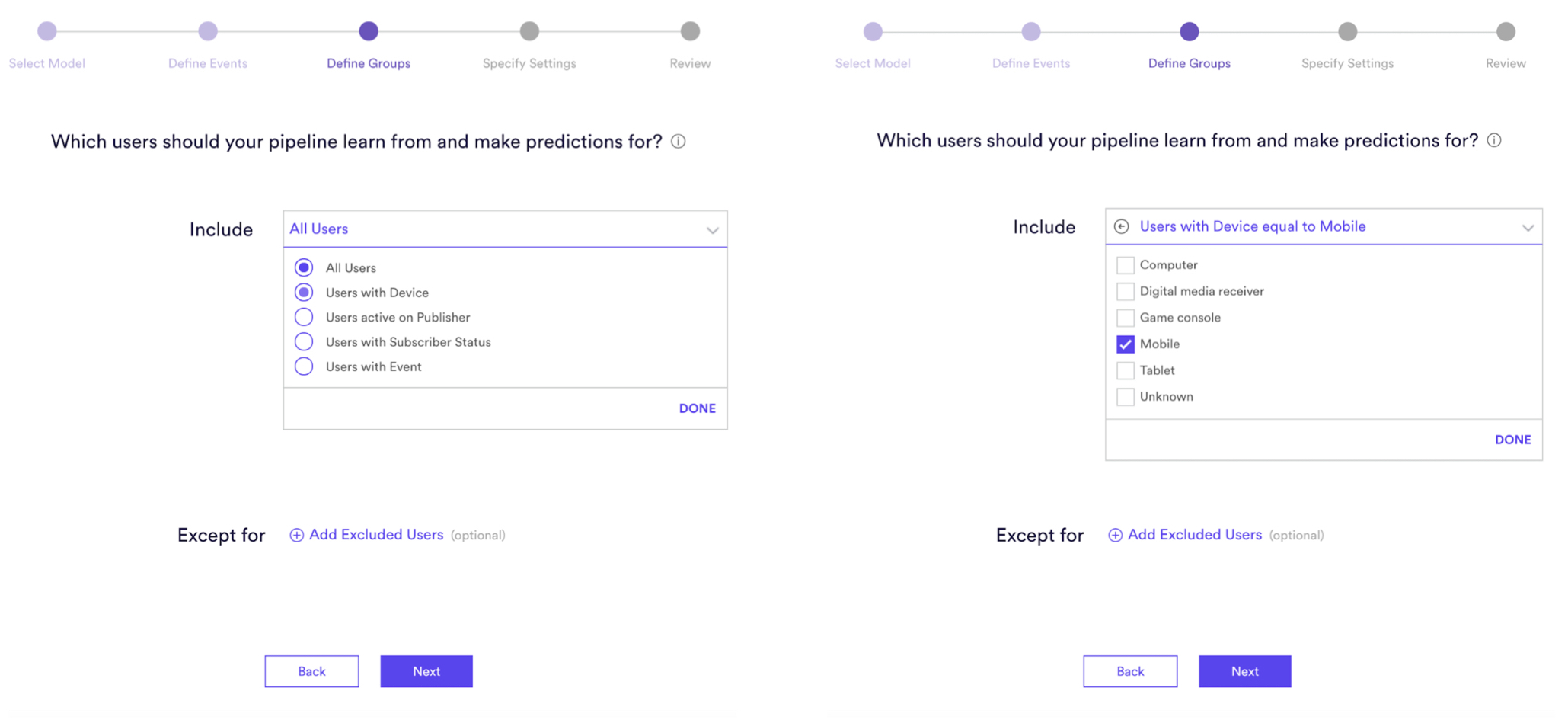
Cortex provides a variety of options for specifying the set of users to train on. This includes specifying attributes like location, behavioral events, devices, websites, subscription status, etc. We’ve tried to make it really easy for marketers to build the highest performing models in the shortest amount of time.
Creating the Best Marketing Models
Machine learning will become an essential tool for marketers in the coming years. As a result marketers will need to become increasingly familiar with how to get the most out of each model they build. Stay tuned for secrets for marketers in the coming weeks.


