
Deploying Machine Learning algorithms at scale for automation is challenging. To solve this problem, AutoML deals with the challenges of building Machine Learning models including the pre-processing of data. But after the models are built, one needs to leverage the output of the models in a way that’s easy for the entire organization.
Background Info on Cortex
Vidora Cortex is an AutoML platform. We provide two principal ways of engaging with Cortex :
- Real-Time APIs: low latency, scalable, and designed for real-time updates. You should typically use Cortex APIs are typically for real-time updates of UIs (e.g. product recommendations, module row order optimizations, etc). You should also use Cortex APIs for other tasks which require the models to update quickly based on user behavior. Today, Cortex APIs process ~50 million requests daily across sites like News Corp, Walmart, and Yahoo! Japan.
- Cortex Queries: more powerful and flexible than the APIs. Cortex enables companies to integrate Strategic AI into their organizations quickly and easily. It also helps businesses optimize for their key strategic goals. Therefore, by using Cortex, businesses can typically begin showing the value of AI and machine learning in weeks vs. years. However, Cortex Queries are not typically used in low-latency situations. Possible queries include:

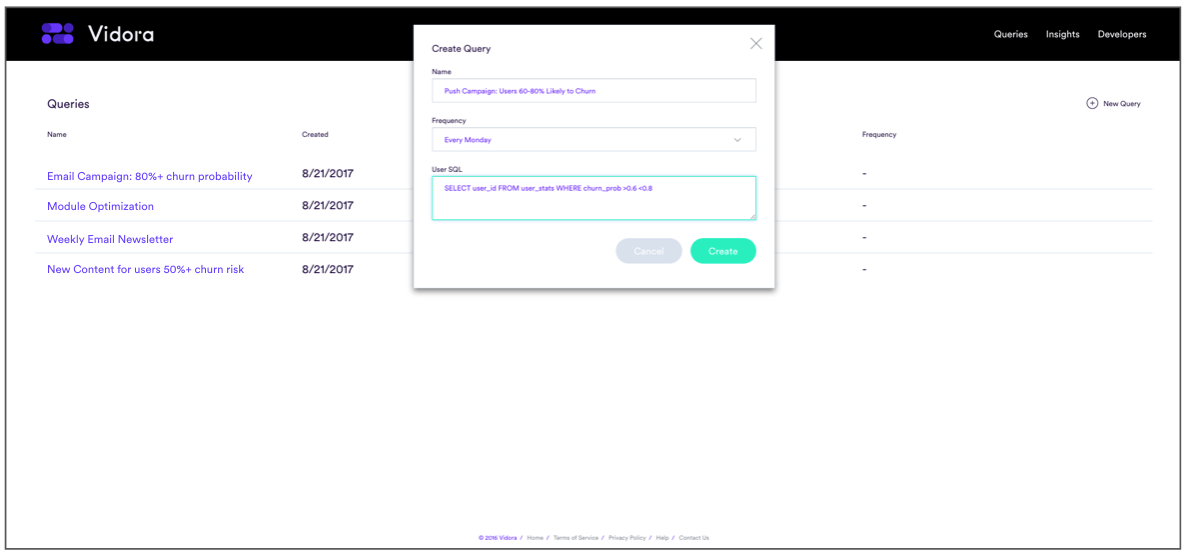
Screen shot of Vidora Cortex which enable AutoML for anyone in an organization.
Module Optimization APIs
Vidora is constantly extending the functionality of our APIs. Recently we pushed out the Module Optimization API . This API leverages Cortex in order to determine the right order of modules in the UI. By doing so, it can maximize a specific goal. Our partners are seeing anywhere from a 10-25% increase in engagements by leveraging the module optimization API.
A typical call to the Module Optimization API looks like this:

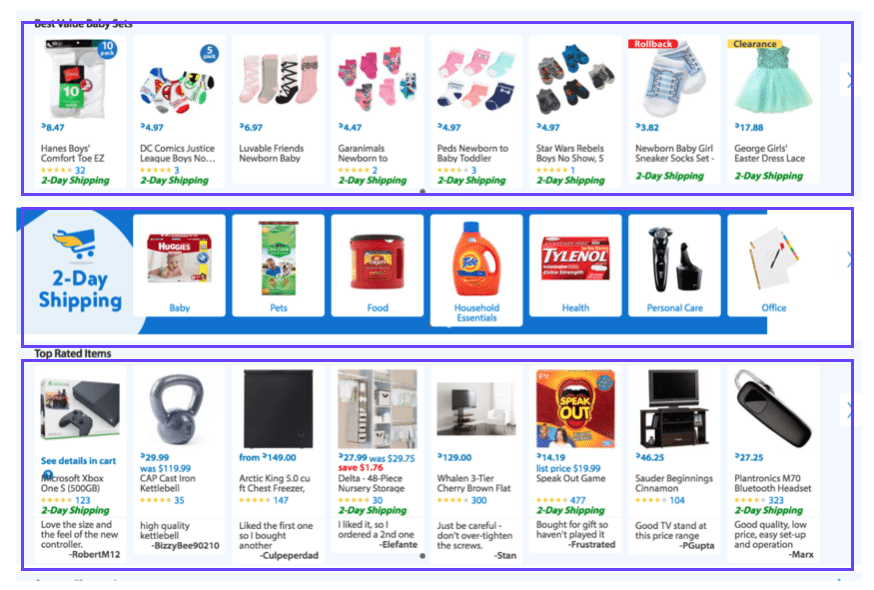
The Module Optimization API, powered by Cortex. Use the Module Optimization API to optimize modules
Vidora designed Cortex to meet the varying needs of our partners. Cortex provides numerous ways of engaging including a low-latency, scalable API and a more flexible framework of Cortex Queries. If you want to learn more please email us at info@vidora.com and check out our product at http://app.vidora.com.


