Enterprise business teams are under increasing pressure to interpret and analyze data in order to drive meaningful improvements in both top and bottom line KPIs.
The most savvy teams are moving beyond data analytics to predictions, but certain challenges remain. Many business teams lack data science resources, know-how, and live with data housed in multiple siloes or lakes.
With the advent of AI 2.0 solutions, some of the most complex machine learning and data science processes around developing, operationalizing, and deploying AI projects are increasingly being automated – in many cases at a fraction of the time and resources associated with traditional in-house AI projects.
Vidora’s mission is to develop, collaborate, and participate in the new AI 2.0 ecosystem, enabling business teams to access the benefits of machine learning and AI.
We are pleased to kick off our inaugural series with one of the most requested AI use cases: Churn Prediction.
In light of recent market conditions and the resulting paradigm shift in consumer behavior and psychology, product and marketing teams need to better anticipate and predict behaviors in order to develop and test new strategies to engage and retain their customers.
In Part 1 of our Predicting Churn series, we walk through two main areas:
-
Data flows
The all-important data flow and integrations that are critical to streamlining machine learning automation with existing data silos, warehouses, and analytics systems.
-
Pipeline setup
Setting up a pipeline to run a churn prediction takes just a few minutes. Here are the 3 top considerations when setting up a prediction pipeline for driving actionable business outcomes:
- What segment of users do I want to run a prediction for?
- What segment of behavior do I want to run a prediction for?
- How often will I need my prediction refreshed given my current rate of data ingestion, analysis, and action?

Contact
Contact us using the form below to learn more about Vidora. We’re excited to hear from you!
—Read the full interview below—
Aaron Huang:
Hey, everyone. I’m Aaron. I’m the head of product marketing. We have Shawn here. He’s our head of sales engineering and overall solutions consultant. Today we’re going to walk through a pretty popular use case. I know it spreads across business folks of all verticals, especially in light of some of the recent events around pandemic, and also some of the market conditions, really having the opportunity to dive into how to look at the data, but also predict churn.
So we’re going to talk about this. But first, a few notes for those of you that don’t know about Vidora, and Cortex in general. We’re going to give you give a quick overview, and then we’re going to dive into the use case and see how you can apply it to your team and your organization. So with that, here’s Shawn. How’s it going, Shawn?
Shawn Azman:
It’s doing great. Great to talk to you today.
Aaron Huang:
Okay. So I know we talked earlier about setting up a demo for people. I guess very, very high level. What are we going to be showing us? What are you showing us today very briefly?
Shawn Azman:
Today we’re going to walk through how to use Cortex, which is Vidora’s machine learning platform. We’re going to start creating machine learning pipelines, which essentially takes all of the user data that you’re already capturing and predicts that into the future. We can take any of those actions that users are taking for predictions. We can predict that they’re going to purchase. We can predict that they’re going to interact.
Shawn Azman:
But today we’re going to focus on a very specific type of prediction, which is churn through inactivity. Essentially what that means is predict the likelihood for every user that they’re going to take any action within a certain time period. The idea being, those users least likely to take any action are probably those users most likely on their path to churning from the service. So this prediction is really going to help us try to mitigate those churn for those users.
Aaron Huang:
Gotcha. When you say users, let’s qualify that a little bit more. I know the spectrum of ML and AI-enabled products out there can go anywhere from the very technical folks that actually need a lot of instrumentation to call it very Wiziwig type systems. Who are we talking about specifically today when we talk about users?
Shawn Azman:
When you think about Cortex, specifically it was built to help automate as much as the machine learning process as possible. So our interface, as we’ll walk through later in this conversation, is extremely user-friendly for even people who aren’t data scientists or aren’t super technical engineers. It’s really meant to be more for a business user. The idea is, once data is being sent over to Vidora, and the idea is that’s going to happen continuously, say, every day new data’s going to be dropped into Vidora, from that point, anybody within an organization should be able to create prediction. So this churn prediction that we’re going to go over today probably is going to be most useful to a marketer. This marketer does not have to be a technical marketer. They could be, for example, in charge of the email campaigns. Perhaps we’re going to do a churn mitigation at the end of the week. The person in charge of setting up that email campaign should absolutely be able to create this prediction.
—Data Flows In and Out of Cortex—
Aaron Huang:
Gotcha. Okay. So I don’t have a data scientist on staff, or if I do, they’re super busy on something else, like fraud detection, a bunch of other use cases. One thing I think we talk about a lot that comes into mind after talking about the end user is how does this actually connect? I know we talked earlier about instrumentation and development. But let’s give people a sense of what the data flow looks like before we set up the use case for them.
Shawn Azman:
When we talk about data flow, it’s obviously how does data get into the platform? And then how does data get out of the platform so that you can use these predictions? So let’s talk a bit about both, because the answer to both is it essentially can happen in one of two different ways.
Shawn Azman:
One way by which to get data into the platform, we mentioned it earlier before, but that is to say, send daily batches of information to Vidora. This kind of information is really going to be around these users that we’re predicting. So it’s going to be behavioral events with a timestamp. So I logged in, I viewed an item, I made a purchase, all of those kinds of events and then any additional information, if you know. This user is a loyalty member, they live in this country. All that information can come over to Vidora. Again, one way to do that is to take the data that you already have, say, stored internally, and then daily send it over to Vidora.
Shawn Azman:
A second way though, to get data integrated, and this is something that we’re going to continue to build on over time, is to hook in directly to the vendors that you’re using to capture this data in the first place. Then, as we mentioned before, once data is in, it’s really easy to create predictions off that. So again, we can create this churn prediction off any data set that’s being ingested into Vidora. Now the question becomes, what do I do with the data once it’s in a prediction form? There’s two ways, and it’s very similar to what we talked about with data ingestion. A lot of customers export to the same source every single time. For example, Salesforce Marketing Cloud, MoEngage, like we talked about before. If you know you’re going to use this information in a specific place, it’s best to just export it there so that you can use it in your campaigns. Otherwise, you can simply download your predictions to a CSV, and then use those yourself. You can either push those back internally to your data warehouse, or ingest it to some other place. So there’s really different ways by which to get data in and out. But it’s really meant to represent the way that you currently work with data internally. So there’s a lot of flexibility into how data can come in and predictions can go out.
—Create a Pipeline in Minutes—
Aaron Huang:
Okay. So as a snapshot we’ve got that behavioral data with some unique identifier. Let’s set up the use case for them now. Data is basically ingested. We’ve got the platform set up. Now let’s talk about the churn use case and walk folks through the actual user interface.
Shawn Azman:
I’m going to go ahead and show you this on a live demo so that we can actually talk through how this is going to work from start to finish. I’m going to go ahead and create a brand new pipeline. But before we do this, I think it’s important to talk about, again, data is everything that is going to power this prediction. So for this demo, we can consider that data’s already flowing into the platform. These are going to be behaviors that these users are exhibiting. So whenever I create a prediction, it’s any of those events that those users are taking that we can use for this prediction.
Shawn Azman:
What we’re going to do right now is essentially trying to project that behavior into the future. That’s why we call this a Future Events pipeline. The idea is based on all the usage patterns that we’ve seen in the past from all of our users, find patterns in that usage, and then predict that into the future so that we can start to see what are these users behaviors going to look like seven, 14, 30 days from now?
Shawn Azman:
So going into the Future Events, the first thing that you’ll see is a listing of all the events that are being tracked and sent over to Cortex. If we wanted to, say, for example, predict that the users are going to purchase, we could do that. We could predict that a user’s going to add an item to the cart. Anything, we can predict here. But for this particular prediction, we’re going to use a more generalized event here, which is, any event, because the whole idea is we’re trying to predict activity. Or more specifically, inactivity from a user. So what we’re going to say is, give me a likelihood that the user is going to take any of the actions that we’re tracking over a certain time period. Here, we’re going to do it over the next month. So what’s the likelihood for every user in our system that they’re going to perform any action within the next 30 days?
Shawn Azman:
You can choose for whom to do this prediction. For this, we’re probably wanting to make the prediction for all of our users, because inactivity can happen from our most loyal to our, maybe, newest customers. So we don’t need to specify, but you always could. For example, maybe you really only wanted to do this prediction for users who were currently loyalty members. So you could absolutely do that and curtail this prediction just to that group of users. But for here, we’re actually going to keep this to all users for now.
Shawn Azman:
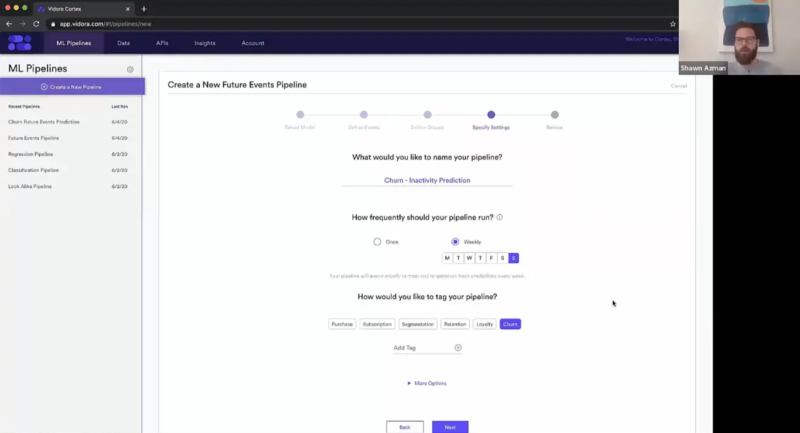
Here, we’re just going to give settings for this. We’re going to call this our Churn Inactivity Prediction. This is a really important part of the setup, which is how frequently should you run this pipeline? Vidora is meant to automate these predictions for you. They’re not just meant to be one-off predictions, and then the next time you want to do this you have to come back and recreate it. Rather, we can have this prediction be always on and always updating. For example purposes, I’m going to have this pipeline rerun weekly and every week on Sunday. What that means is every user on every Sunday is going to get a new prediction score looking 30 days out into the future, predicting their activity or inactivity over that time period. The idea being, let’s say we send a weekly newsletter every week on Monday. Every time we send that newsletter we can rest assured that we’ll have the most up-to-date prediction for every single one of our users within our system.
—On Machine Learning Automation of Predictive Pipelines—
Aaron Huang:
Let me pause you here real quick, because I see the notion here of a pipeline. Obviously, when in the AI and ML parlance people really do understand this notion. But when we break it down here, from the previous discussion we were having around data flows, what exactly is happening in these pipelines? How quickly am I, a marketer, able to basically launch a churn prediction like this? Because one of the questions I usually have is, this is great. This is a great demo, but this could take months for me to set up. I actually did a previous project like this in-house, and it took over a year. So what is the discreet steps here when we talk about pipeline specifically?
Shawn Azman:
That’s a great question. This is actually a question that we hear from a lot of our customers all the time. I’ve actually experienced this personally in my past work history where we’ve hired teams internally to build AI and ML. Oftentimes, what you find is the estimated time that it’s going to take to get started with AI and ML is usually underestimated. Usually it takes longer and requires more resources than you typically think. That’s where this machine learning pipeline concept really comes into play. Because when we talk about a machine learning pipeline, it’s not just selecting an algorithm on which to make a prediction, because there’s so much work that goes into creating machine learning that happens before you even pick an algorithm. Even though that’s typically what we think about AI and ML, is that an algorithm that gives us predictions.
Shawn Azman:
But what we don’t often think about is what are the steps that lead up before we can even run an algorithm on our dataset? Well, first we have to aggregate it. Then we have to clean it. Then we have to process it. Then a very important part of machine learning is what’s called creating features. Essentially what that’s doing is taking all of the raw data that you’re capturing about these users. The fact that I clicked on an item seven days ago, I bought the item four days ago. It’s taking all these individual events and it’s summarizing them. It’s creating these features out of them that are going to be the basis of our predictions. So this concept of going from raw data to aggregated, cleaned, and featurized data, that’s typically where we see most of the time spent in machine learning pipelines. Simply getting data into a format on which you can run your predictive algorithms and models and get these predictions.
Shawn Azman:
Everything that we’re doing right now in setting up this machine learning pipeline is meant to automate all of those steps. We have data coming into the platform in raw form. User performed this event at this time. That’s all the data that we’re getting. What we’re able to do is automatically aggregate, clean, process, and featurize that data so that anybody within the organization can think of a business question and create a prediction that way. As you can see here, I don’t necessarily have to say, “Create this feature from this data and do maybe really complex coding,” as if I were an engineer. All I have to do is come up with a business question. My business question here is, which users are most likely to go inactive in the next 30 days. By phrasing the question in that way, I can then get those predictions. Now, I’m off to the races to use that, maybe in a marketing campaign, maybe within my product. So from start to finish, as you can see here, it’s very quick to create those pipelines.
Aaron Huang:
Gotcha. On the churn predictions, I know this is also one of the questions. We’re getting a little bit fine grain here, because we’re talking about inactivity. One question I think you hinted on around loyalty and that sort of behavioral segmentation, how many different segments can I run this experiment on? How many concurrent experiments? This also goes into the question of how quickly we can actually launch these. One of the business challenges from my perspective would be, how do I demonstrably show ROI as quickly as possible to my C-levels? That’s also predicated on not just speed, but also segmentation, and the ability to run concurrent pipelines. So how does this use case translate to that? And how many of these other predictions can we actually run at the same time?
Shawn Azman:
I want to answer your question by going back to the initial settings, which is our machine learning pipelines. As you can see, I have multiple machine learning pipelines that are currently active within my account. This is really the beauty of Cortex, because typically when you think of building machine learning internally, oftentimes it comes down to creating machine learning per prediction. If I want to do a churn prediction, I have to do all of the machine learning pipeline steps to get that. Get the data, aggregate it, process it, clean it, featurize it. Then let’s say a few months down the line, I want to change and create a different prediction. I want to predict purchases. Well, typically you have to go through those steps again. Find new data, clean it, process it, so that I can do another prediction. What you find is that there’s a lot of overhead in those early parts of the process of organizing and cleaning this data to get those predictions.
Shawn Azman:
Vidora automates all of that. What that means is, of all of the data coming into the platform, you don’t just create one prediction. Rather, you can create as many predictions as you need off that same data set. For example, if I wanted to, we just created that churn prediction. I can go right back in and start to create a purchase prediction. Who’s going to purchase in the next seven days? The beauty about this is it’s coming from the exact same dataset that our other predictions are coming from, and it can be updated in the same fashion. So this can be automatically updated, say, on a weekly cadence, for the most accurate predictions.
Shawn Azman:
So there really is no limit in terms of how many predictions that you want to create on top of the data that’s already being ingested.


