Watch our ongoing series on how automated machine learning can accelerate personalization strategies and ROI for enterprise marketers and product managers.
Converting Anonymous Users to Registered Users [Part 3]
Automated machine learning solutions for business and data teams can be a powerful competitive advantage when 3rd-party cookies can no longer be relied on.
Companies like The Wall Street Journal are at the forefront of leveraging tools like Cortex to power machine learning on their first party data to better classify and segment their readership.
In the final part of our series on converting anonymous to registered users, we’ll walk through the results of data that has been fed into Cortex and automatically trained.
You’ll get a peek at how to leverage these predictive results to hone in on the most likely behaviors that drive registrations and subscriptions.

Contact
Contact us using the form below to learn more about Vidora. We’re excited to hear from you!
—Read the full interview below—
—Interpreting Predictive Results—
Aaron Huang:
All right, well thanks Shawn. And now that we’ve completed and trained up our pipeline, I know it’s been running for a few minutes, so we had time to go take a coffee break. Now that we’re back, let’s walk through the results. And this is actually one of the more important points about our earlier discussion around testing out the veracity of the results and seeing some of the back tests here. So let’s walk through that with you.
Shawn Azman:
Definitely. Yeah, so we have the pipeline. It’s been trained. We now have predictions for all of our users. So what we can do now is kind of look behind the scenes. We have talked about before that typically, if you’re trying to do this manually, there’s often some guesswork or some trial and error that you need in terms of finding the best features for your model, and then choosing the right model, particularly for this prediction.
Shawn Azman:
So as we go into pipeline discovery, what we’re going to look here is all of the features that we created off the data that’s been sent into Cortex. So here, for this pipeline, we have 65 of those features. And what we’re going to try to do is show you automatically, what is the most important features that lead to this prediction? Or said another way, what types of behavior for each of these users lead to a very accurate prediction. And what we’re going to look here is, all of the features that Vidora created specifically for this prediction pipeline. And it’s split up into two groups, active days and event types. And you can see all of the different features that we created for day activity, as well as all of the events that we created, and all of the features that we created off those events.
Shawn Azman:
For example, one event is that a user viewed an item, but as you can see, we’re going to convert that into many different features that are available for this pipeline. But if we even take it at a very high level, what this is telling us is that it’s actually not the type of behaviors that our users are taking that leads to a very accurate prediction for this particular pipeline. Rather, for this particular pipeline, what we’re seeing is that it’s the user’s activity in terms of how many days they’ve been active that is leading to the highest predictions, which kind of makes sense here. For these anonymous users, before they become subscribers, simply seeing repeated and continuous activity over time is probably more important than the individual actions that they’re taking within your service.
Shawn Azman:
So that’s exactly what we’re seeing here. As you can see, the importance, which means what is the importance of this particular dataset to the overall prediction, active days is much more important than the types of events that they’re taking. So it’s very interesting to see for this particular pipeline. And now, that isn’t to say that this will be the right data for your pipeline. Obviously, your dataset is going to impact what we see here. This is just for this dataset that we’re running.
Aaron Huang:
Well arguably, a subsequent pipeline that I could actually run as a prediction would be, what are some of the actions that actually draw a user to come back and engage with the content again.
Shawn Azman:
Yeah, yeah. Definitely, and you could even put it the other way, which is you can make a prediction on a specific type of content. And we see this a lot with our media companies, especially ones that have release schedules. Let’s say you’re a media company and there’s a new season of a TV show coming out. You may want to make a prediction based on all of the viewing patterns of your site, who is most likely going to watch this particular TV series. And in the weeks leading up to the premier, you could do a lot of marketing and make sure that you’re hitting people who have some interest. So yeah, there’s definitely different ways by which to do this. It’s really all about what are you trying to predict, and more important, what actions are you trying to take off the prediction? Be it in the product or in marketing. So yeah, a lot of really great things you can do.
Shawn Azman:
And the nice thing is, as you mentioned, is you can do this as a different pipeline off the same dataset. So as long as we’re getting those new usage patterns, you can create as many different pipelines as you need within Cortex, all off that same dataset. And again, that really opens up the possibilities, especially for maybe in marketing or product teams who haven’t had access to machine learning in the past. Really now, machine learning’s at your fingertips, and you can create as many different predictions as you need.
Shawn Azman:
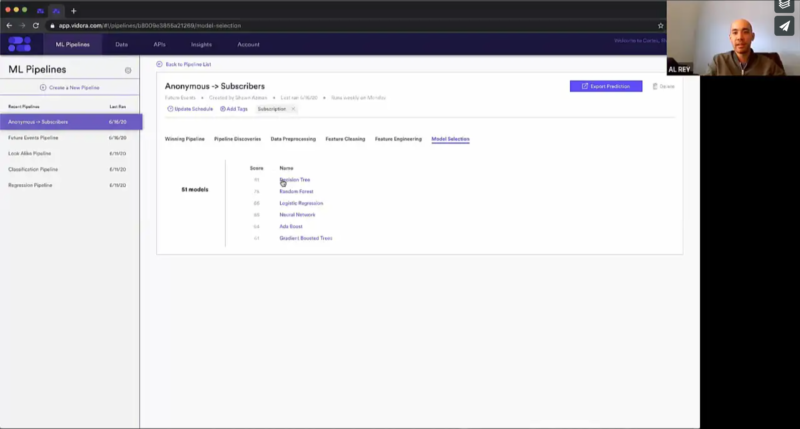
And so as we create this pipeline, again, these features are going to be automatically created, but that’s only one step. Once we have the features, then we need to put them into a model. And we give you all of the information that we did behind the scenes in order to choose this model. So we can see here for this test pipeline, decision tree is the model that we chose. And you can see the stack rank of all the other ones that we tried. But it wasn’t that we just blindly chose to do a decision tree. As you can see here, we’re going to test multiple versions of this model.
—Machine Learning As A Service – Automatically Selecting the Best Model—
Aaron Huang:
Got it, and I know we were talking before about how to essentially verify that the model that was selected is indeed the model that gets the best predictive results versus our control. So on some of the graphs here, why don’t you walk through sort of how Cortex actually runs, or show that?
Shawn Azman:
Yeah, definitely. Because as you’re running these predictions, obviously the only data that you have at your fingertips is past and historic data. And so when we train these models as you’re seeing here, and give these winning models scores and the overall score for the model, we can only make that score off the historic data that we’ve seen in the past. And really briefly, the way that we do that is we essentially look in the past of your data, and we take two sets. The majority is going to be our training set, which we’re going to give to the model and learn all those behaviors to create our prediction. But then there’s also a subset which is a holdout group, and this is how we see if the model actually has predictive value based off this historic data.
Shawn Azman:
We’ll train the model, and then run it on these users, essentially asking the question, if we had this predictive model in the past, would we accurately have predicted these users’ behavior? And so that’s how we’re going to choose the winning model, determine these scores and then pick the model for you for this pipeline. However, one of the things that we’ve talked about, and especially given the time that we are in 2020, these behavioral patterns can change quite drastically and quite quickly. And so what we want to prove is, is the model that we trained in the past still accurately predicting our users’ behavior in the future? And so we have our demo environment set up here, and what we’re showing you is tracking this users behavior over the next 30 days.
Shawn Azman:
So we made this prediction on June 15th, and again, this is just a demo environment, so we’re going to predict this data into the future. But this would actually be tracked in real time for your account. So on the day that we made the prediction, there’s going to be no data here, but one day, two days, so on and so forth, after this prediction, we’re actually going to track each user’s explicit behavior and see if that matches up to our predictions. Specifically, what you’re seeing here is we’re going to take the top 10% of users we think are most likely to do this action. In this use case, it’s going to be the top 10% of currently anonymous users who we believe are going to be subscribers within the next 30 days. Similarly, we’ll take our lowest 10%, we think are least likely to perform this action. And then right in the middle here, what you’re seeing is a randomized control group, a random 10% of users chosen from all the users we’ve made this prediction.
Shawn Azman:
And this is really a litmus test, because as we again, one, two, three days after our prediction, when we start to see this data, what we want to know is are our highest propensity users converting at a clip higher than our control, and at a rate higher than our low propensity, and that’s exactly what we’re seeing here. And this is just showing that the model that we trained in the past off that historic data is not just accurate for users in the past, but as we can see here this is actually accurately predicting users’ behavior for the future.
Aaron Huang:
Got you. This is super powerful Shawn, and it looks like there are already a bunch of other use cases that are popping up in my mind in terms of next steps that we would run here, so this has been great, and thanks so much for your time.


