New feature engineering modules called “variety” features are available now in Cortex! Here’s what they are:
A critical, arguably the most critical part, of machine learning model creation is ensuring you are using the right features in your model. The process of creating features for use by learner is known as “feature engineering”.

– Andrew Ng, Machine Learning and AI via Brain simulations [1]
Vidora automates the entire machine learning process. This includes the ingestion of raw data, all the way to model predictions, including feature engineering. Today, we work with an increasing number of partners. As we do so, we continually enhance and add new functionality to our machine learning pipeline. As a result, often the enhanced functionality includes adding relevant features engineering techniques.
Improving Performance With Cortex
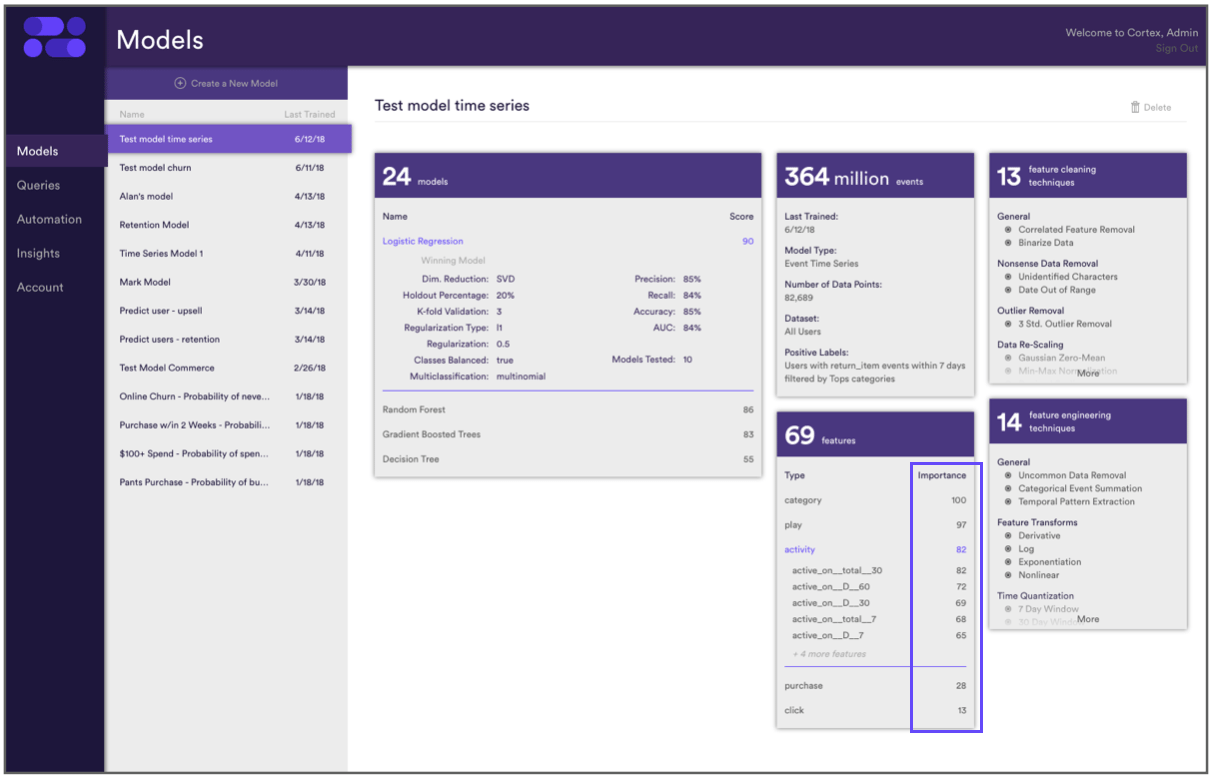
Most recently we found a marked increase in performance for Time Series Prediction Models and Look-Alike models for media and subscription companies. We accomplished this by adding a slew of features related to the variety of content or categories that a user is engaged with.
For instance, one commerce customer might buy items from “pants”, “shirts”, and “jackets”. Meanwhile, another might exclusively buy from “pants”. Therefore, these differences in customer behavior can be useful signals for machine learning models. They can also relate to purchasing propensity, customer loyalty predictions, and customer-lifetime value predictions.
For media companies, also consider a customer who views video content across multiple genres. Then compare them with a customer who views content exclusively from one genre. These differing behaviors can have dramatic impact on key models of interest to media companies including user churn and content recommendations.
Depending on the model and data-set these new features could increase model performance by 5%+.
You can view the relative importance of these new “variety”-based features for various models in your Cortex Models page. Log into your Cortex account by navigating here. See below.