The Results:
5x increase
in segment performance with more samples

in segment performance with more samples
Most major media companies who monetize using advertising are faced with the challenge of building high-quality ad segments. This ad inventory is then sold to brands who are able to target specific audience segments to market themselves. Ad segments are often built with unique 1st party data which the media company uses to “seed” the segment and find more similar users. Given that collecting 1st party data is often challenging and costly, the question naturally arises of “how much 1st party data do I need to create a quality ad segment?”
Vidora worked with a major media company to evaluate how much data was needed in order to build out premium ad segments.
Ad segments which are targeted using a DMP are a key monetization mechanism for many ad-based media companies. The most valuable ad segments are often built using unique, and high value, 1st party declared data. However, collecting 1st party declared data is often costly and time-consuming. The media company was interested in understanding how much 1st party data was needed to build a quality ad segment?
Cortex enabled the media company to quickly build high quality ad segments using seed data. The process of building a seed segment followed the following steps –
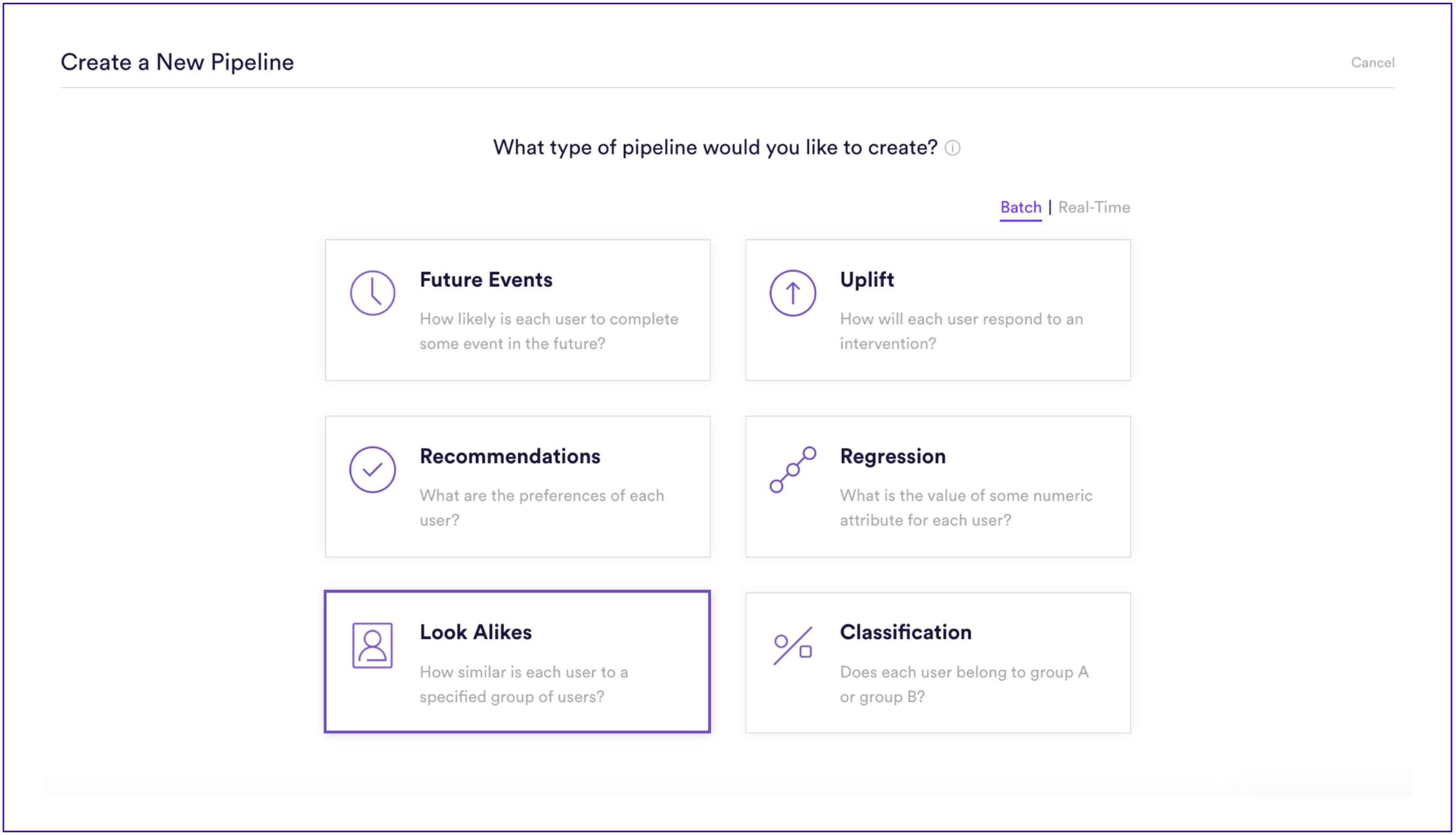
1. Upload seed data into Cortex. In this case “Look-Alike” models were used.
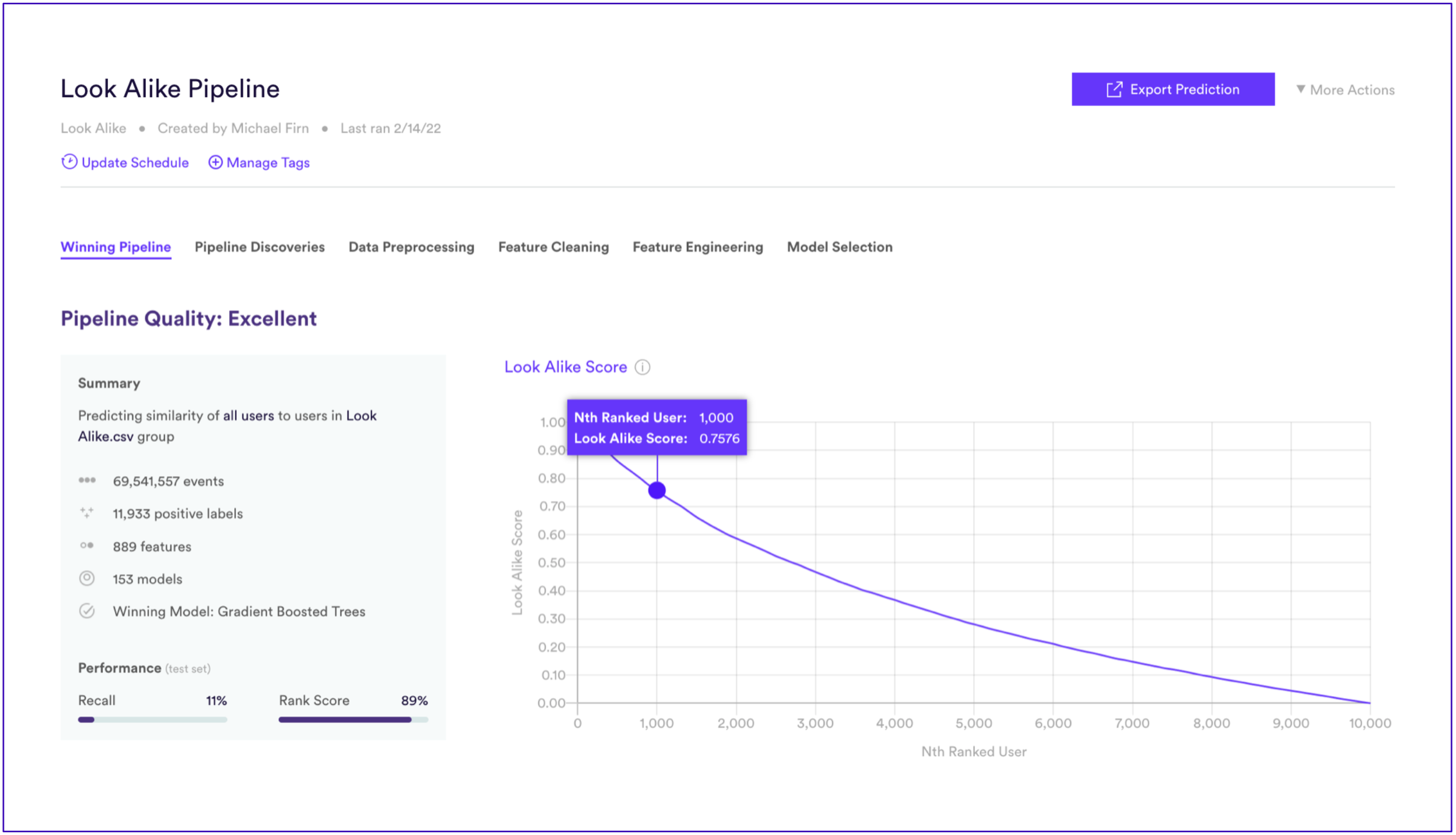
2. Train the Look-Alike model. Note that Cortex contains a variety of high quality semi-supervised modeling techniques in addition to automated feature engineering capabilities with which to build a high quality model.
The media company trained the Look-Alike model using 5 different seed set sizes and repeated the experiment 10 times using different sets of seed data in order to build statistical significance.
Performance was evaluated for each experiment by looking at the average rank of users not used for training. The higher the rank, the better-performing the model.
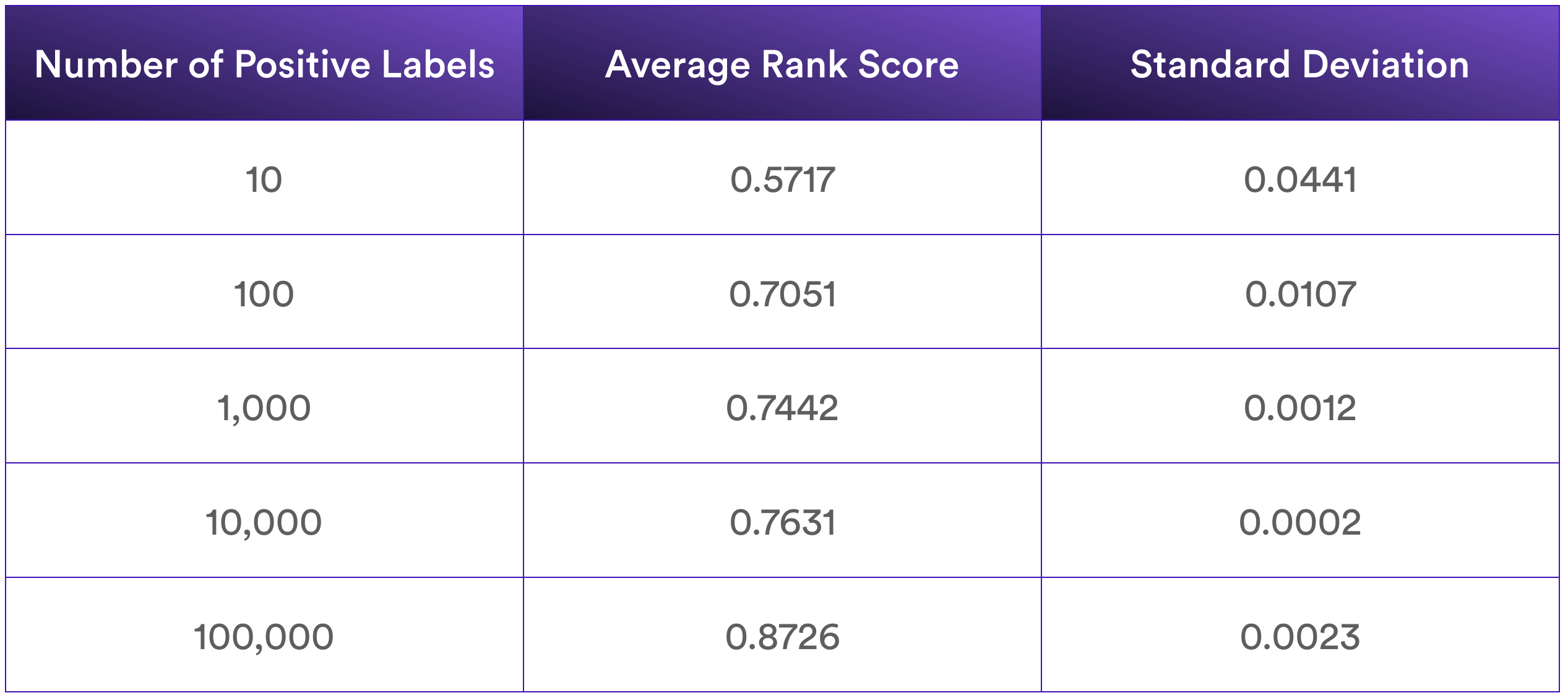
Note that a “random” assigning of ranks would result in an Average Rank Score of 0.5, meaning that even with 10 positive labels there was signal in the Look-Alike modeling. Note also that increasing the size of the positive labels used in the seed set by orders of magnitude always had a positive effect on performance.
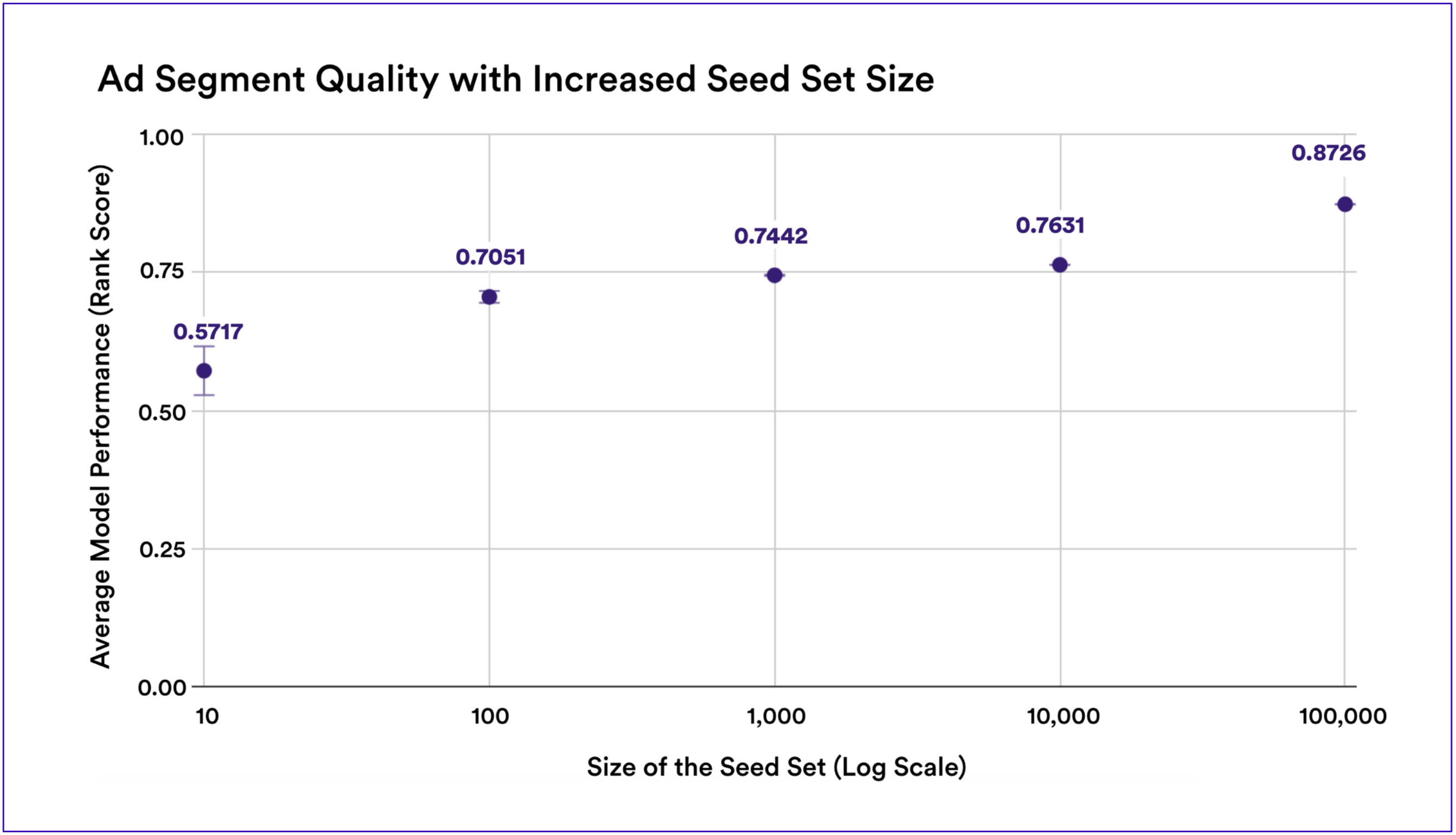
Increasing the size of the seed set increased the performance of the Look-Alike models.
Cortex enables businesses to quickly run high quality machine learning experiments. In this case, a major media company explored the impact of increasing the seed set size on Look-Alike model performance. They found that increasing the seed set size had an impact on performance but that substantially more users in the seed set were needed to impact performance.
Learn More Today


