How Can We Help?
Amazon S3
Once you’ve created a Machine Learning Pipeline, Cortex makes it easy to integrate the predictions into various third-party platforms, including Amazon S3.
An integration with Amazon S3 allows you to deliver predictions from any Cortex pipeline directly into your own S3 bucket. This gives you complete control over how your predictions are deployed, making it easy to move them through data workflows across your business.
In this guide, we’ll walk through how to set up an Amazon S3 connection in Cortex, and discuss the functionality that this integration unlocks within your Cortex account.
Connecting an Amazon S3 Export Destination
A Cortex Export Destination sets up an integration between your Cortex account and a third-party platform. Once the connection is live, you may export predictions from Cortex directly to this custom destination.
To connect your Cortex account to Amazon S3, create an Export Destination by following the steps below.
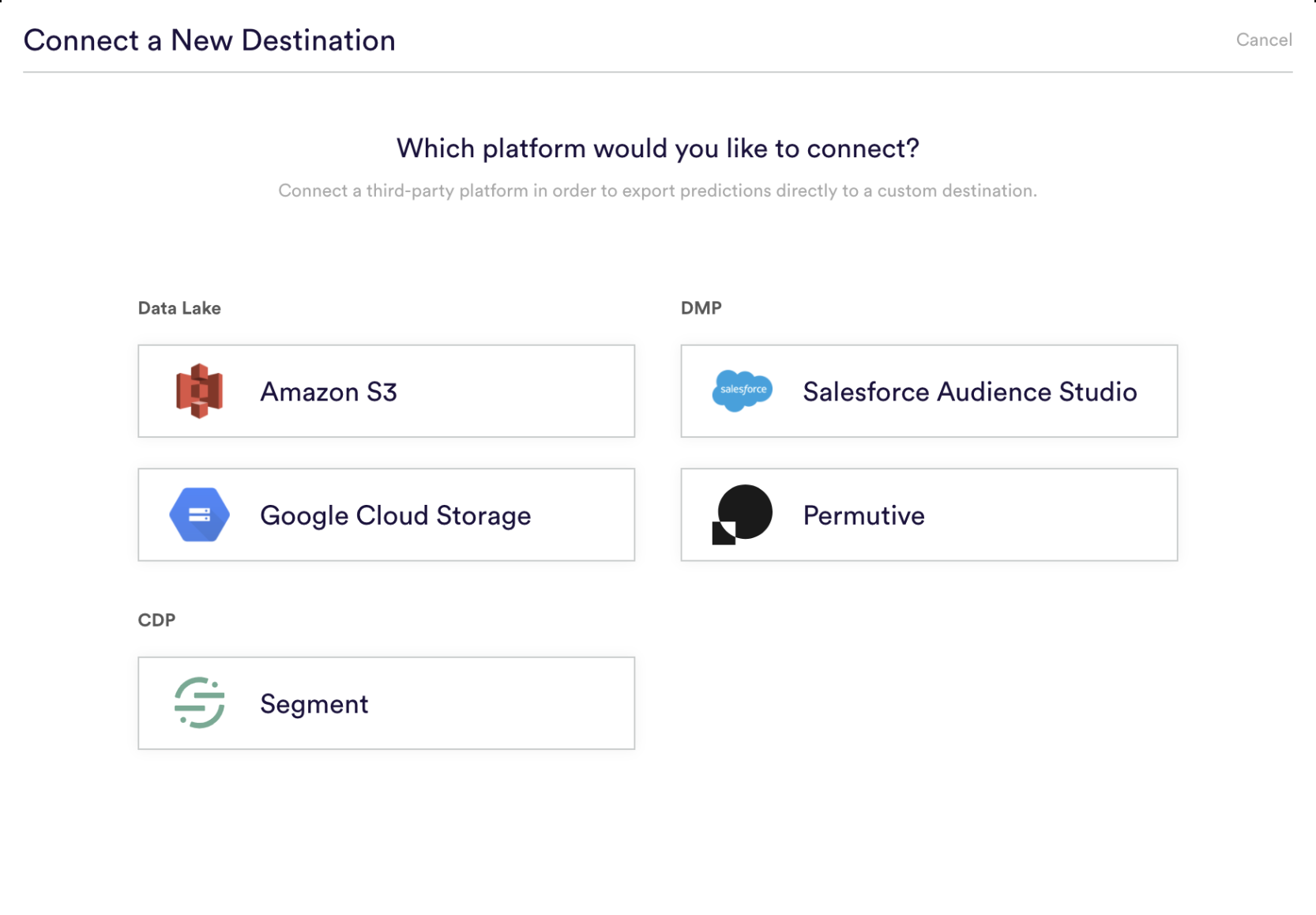
Step 1: Select Platform
First navigate to the Export Destinations area of the Data tab in Cortex, and select the “Amazon S3” icon from the list of available platforms.
Step 2: Name Your Export Destination
Provide a name for your Export Destination so that you can reference it later when exporting predictions from a pipeline.
Step 3: Authorize Cortex to Access the Bucket
Before connecting the export destination, you must first authorize Cortex to access your S3 bucket. This can be done by logging into your AWS IAM console in a new browser window, and taking the following steps.
Create Policy
First, create an IAM policy which specifies the actions that policyholders are allowed to take on your S3 bucket. Later, you’ll attach this policy to an IAM role created for Cortex.
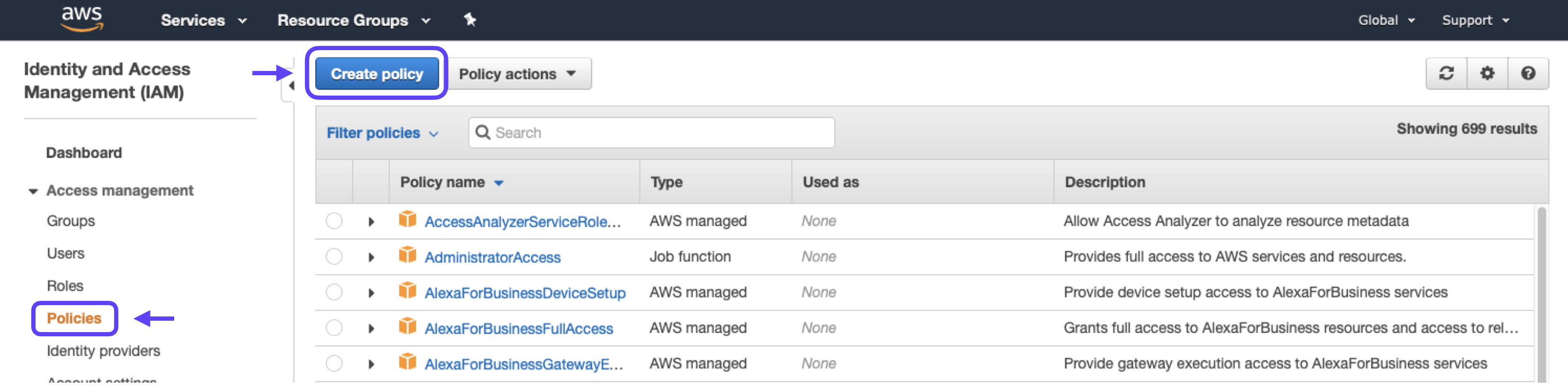
1. Go to the Policies section and click the Create Policy button.
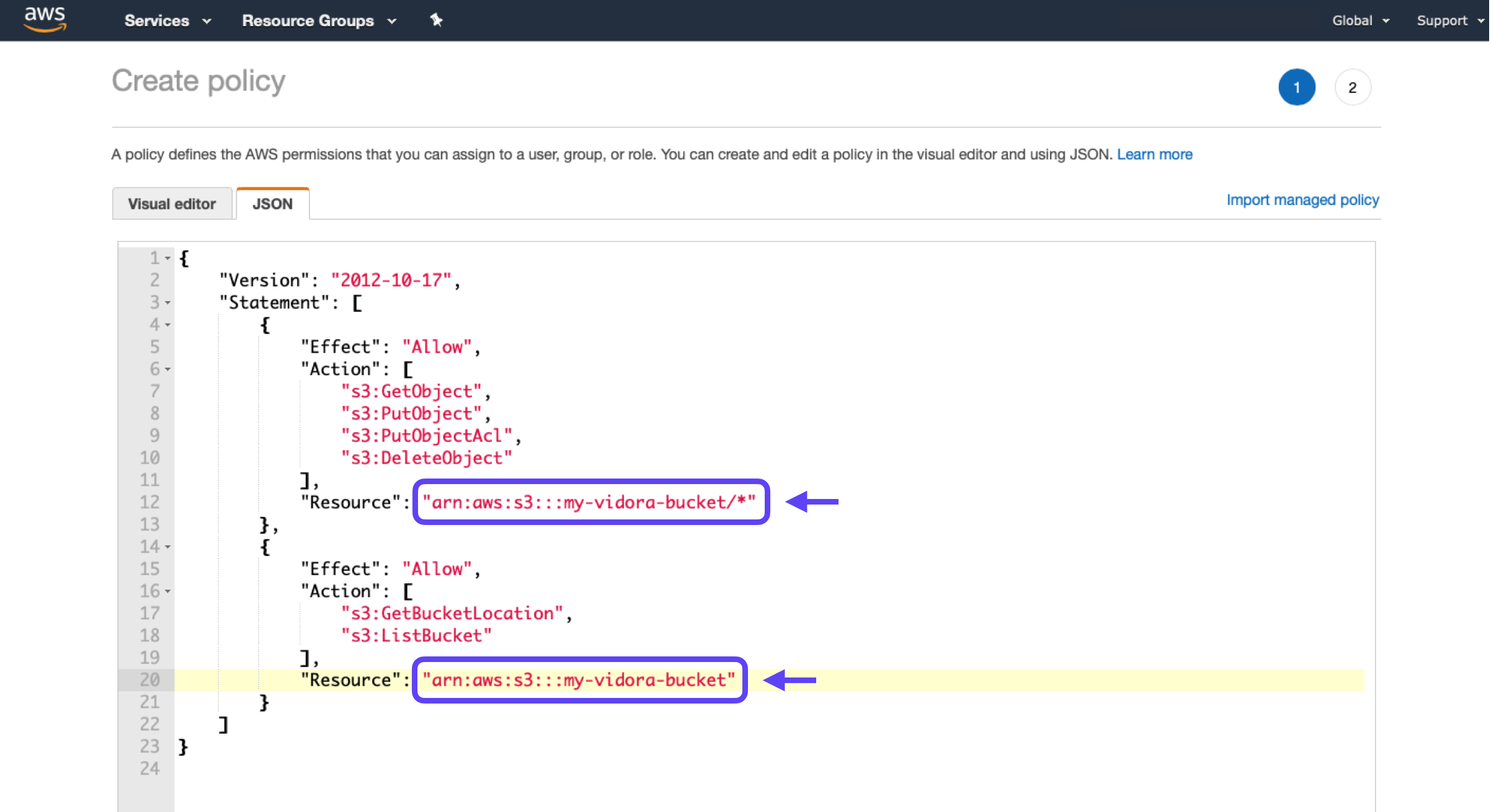
2. Copy-paste the following into the JSON tab. Make sure to replace the YOUR-BUCKET-NAME placeholder with the name of your own S3 bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::<YOUR-BUCKET-NAME>/*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation", "s3:ListBucket"
],
"Resource": "arn:aws:s3:::<YOUR-BUCKET-NAME>"
}
]
}
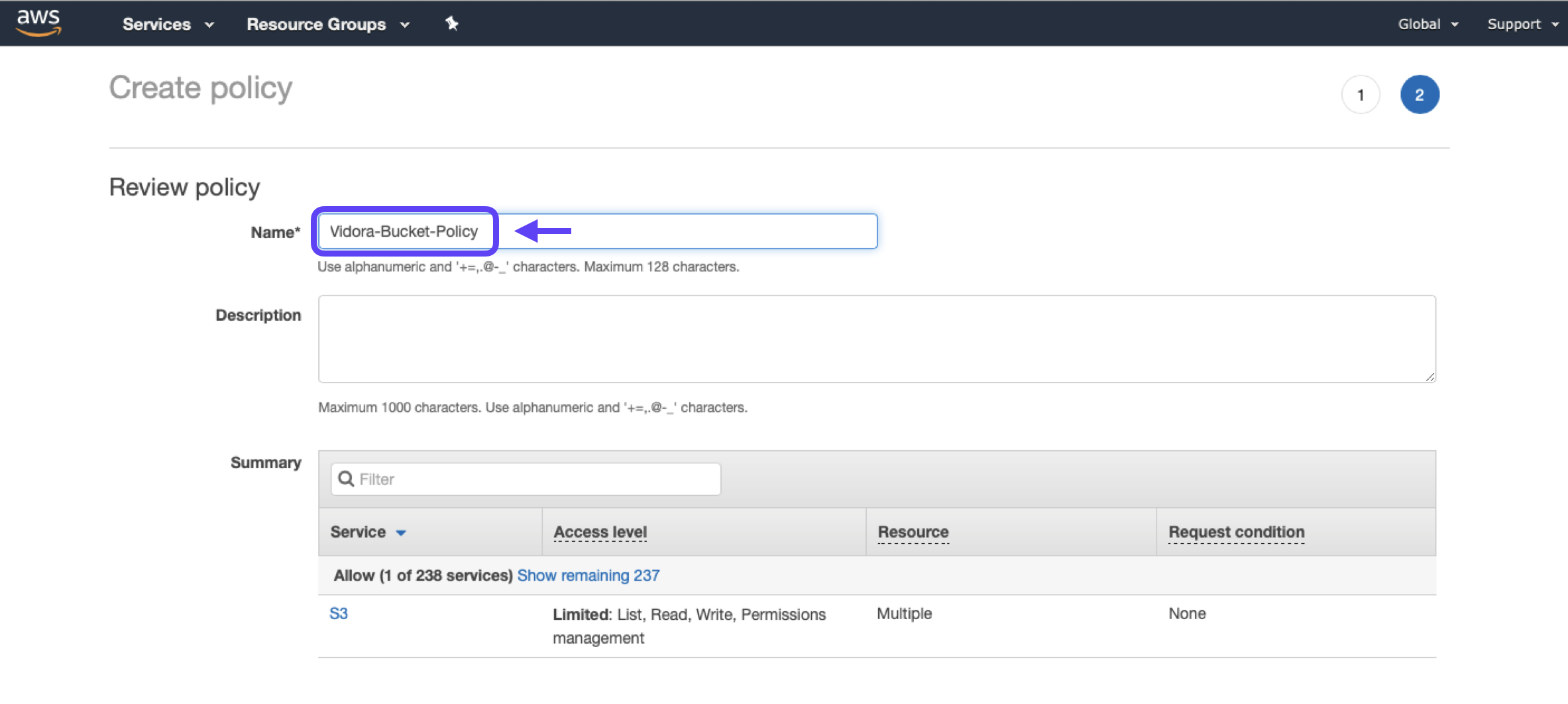
3. Click Review Policy, and provide a name and description for your policy. Make note of your policy’s name (e.g. “Vidora-Bucket-Policy”), and hit Create Policy.
Create Role
Next, create an IAM role which links your newly created policy with Cortex’s AWS account. This authorizes Cortex to take the actions specified in your policy.
1. Go to the Roles section and click the Create New Role button.
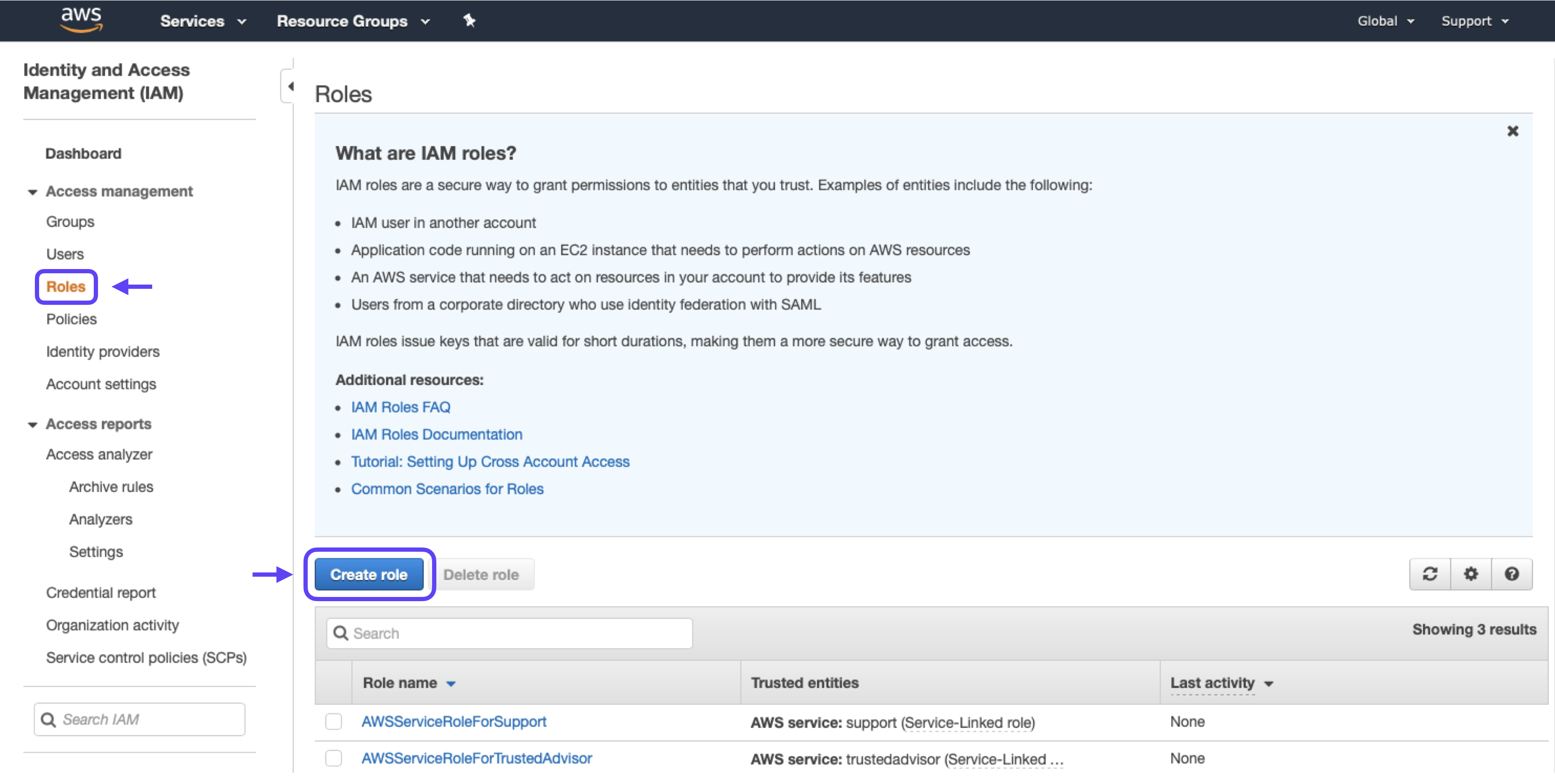
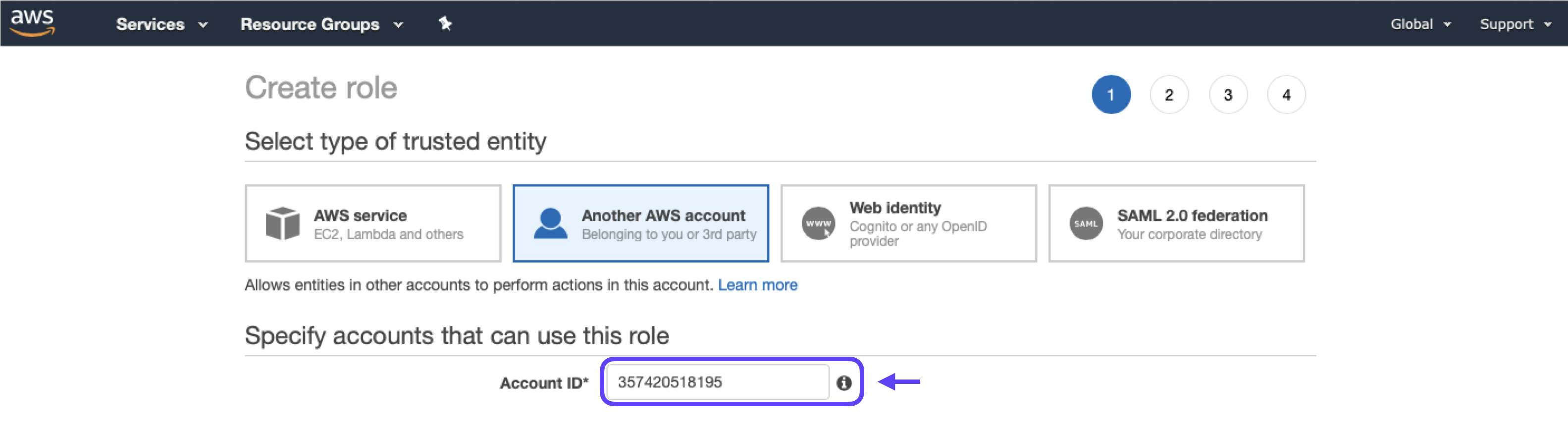
2. Select Another AWS Account, then enter 357420518195 (Cortex’s AWS account ID) in the Account ID field.
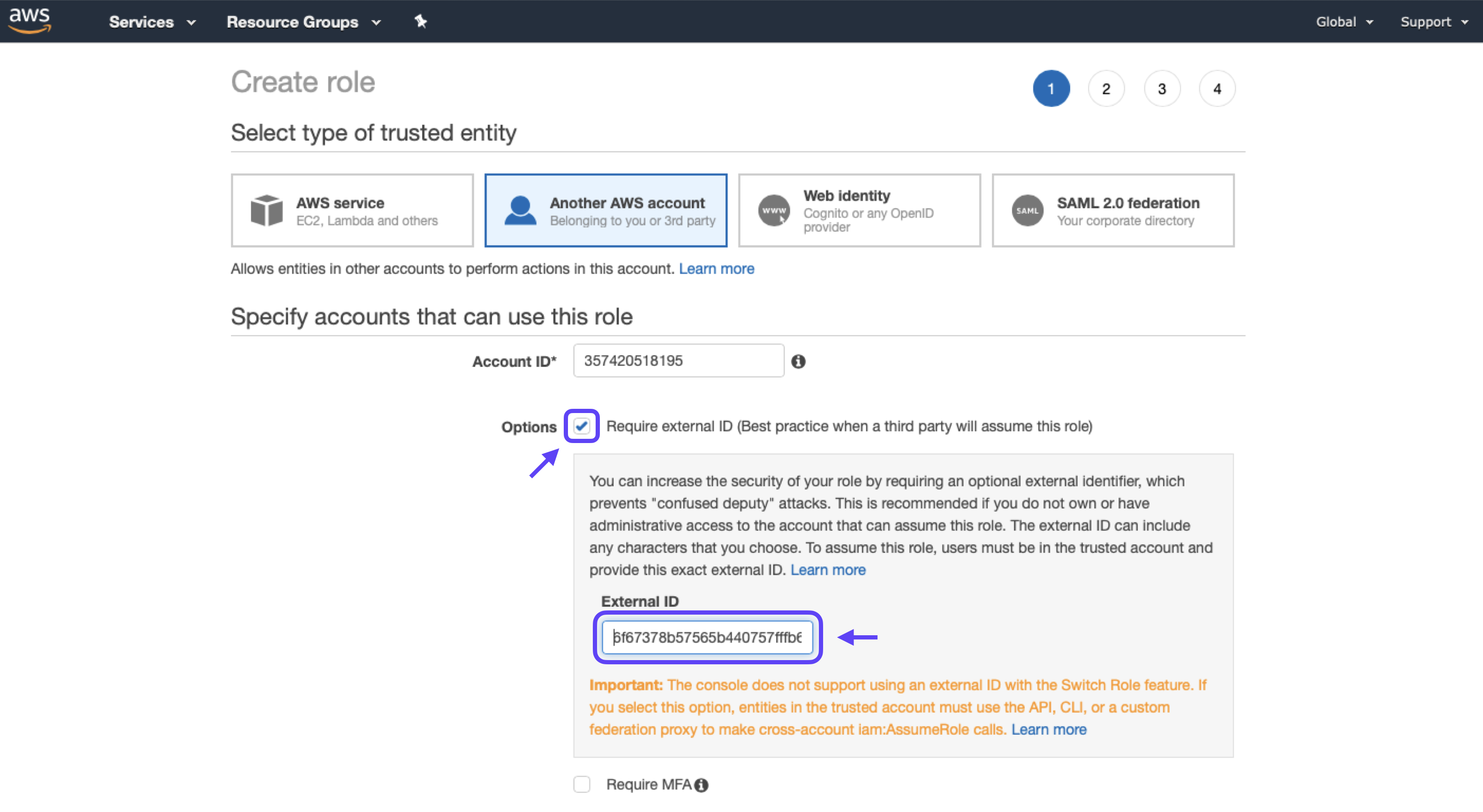
3. Check the “Require External ID” button, and enter the External ID listed in your Cortex account on the “Connect a New Amazon S3 Destination” page.
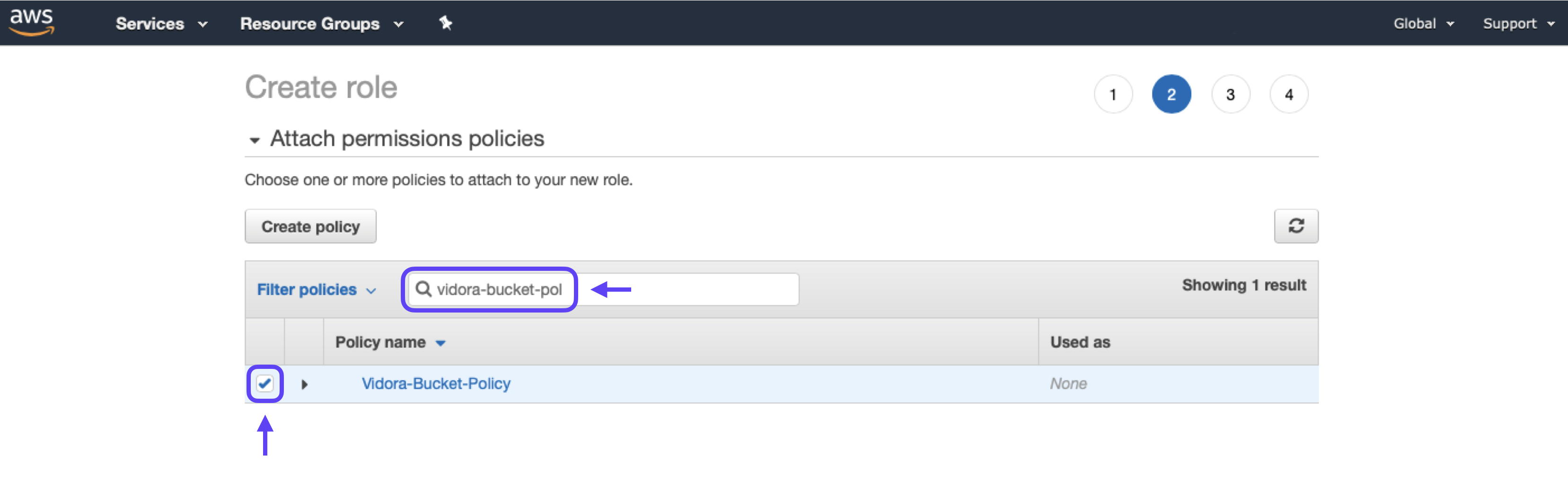
4. Proceed to the Permissions page, and search for the name of the Cortex policy that you created earlier. Click the check-box next to your policy in order to attach it to this role.
5. Proceed to the Tags page. Applying tags to your role is optional.
6. Name your new role (e.g. “Vidora-Bucket-Role”), then click Create Role.
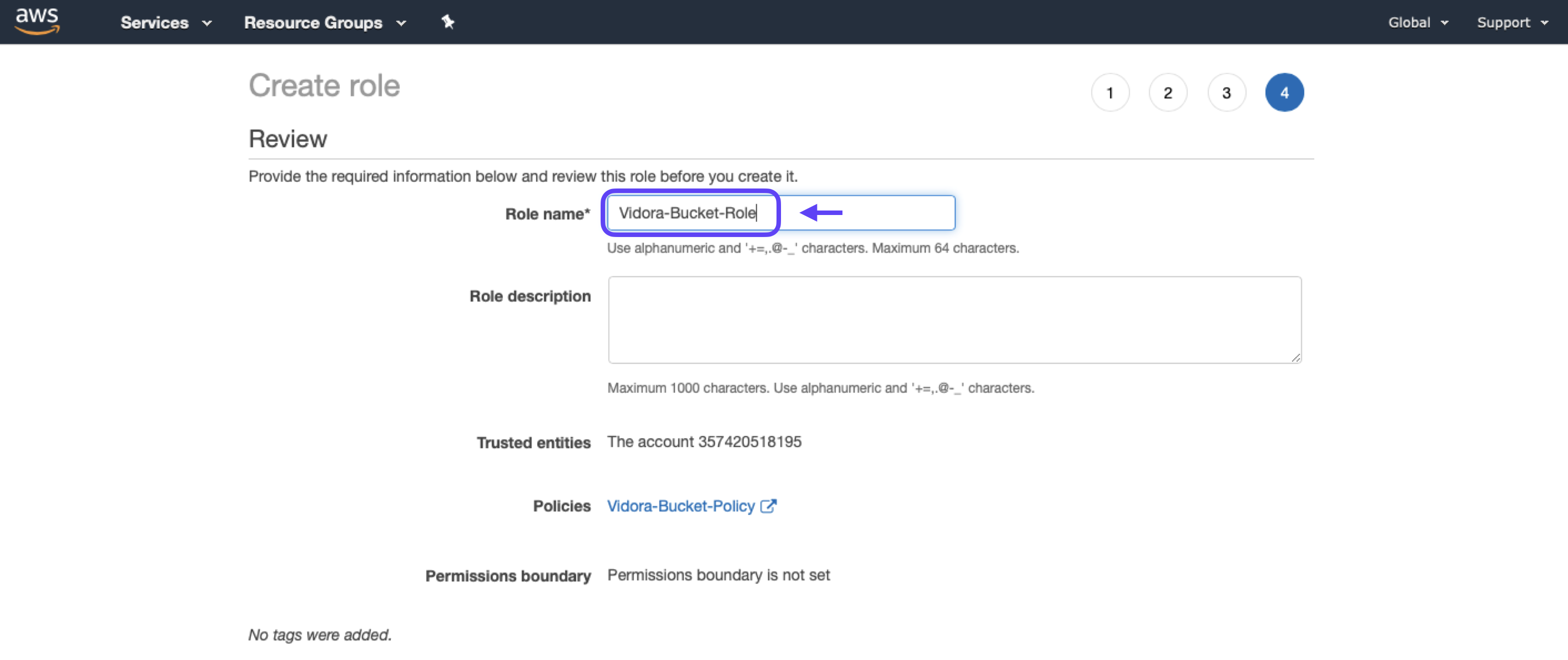
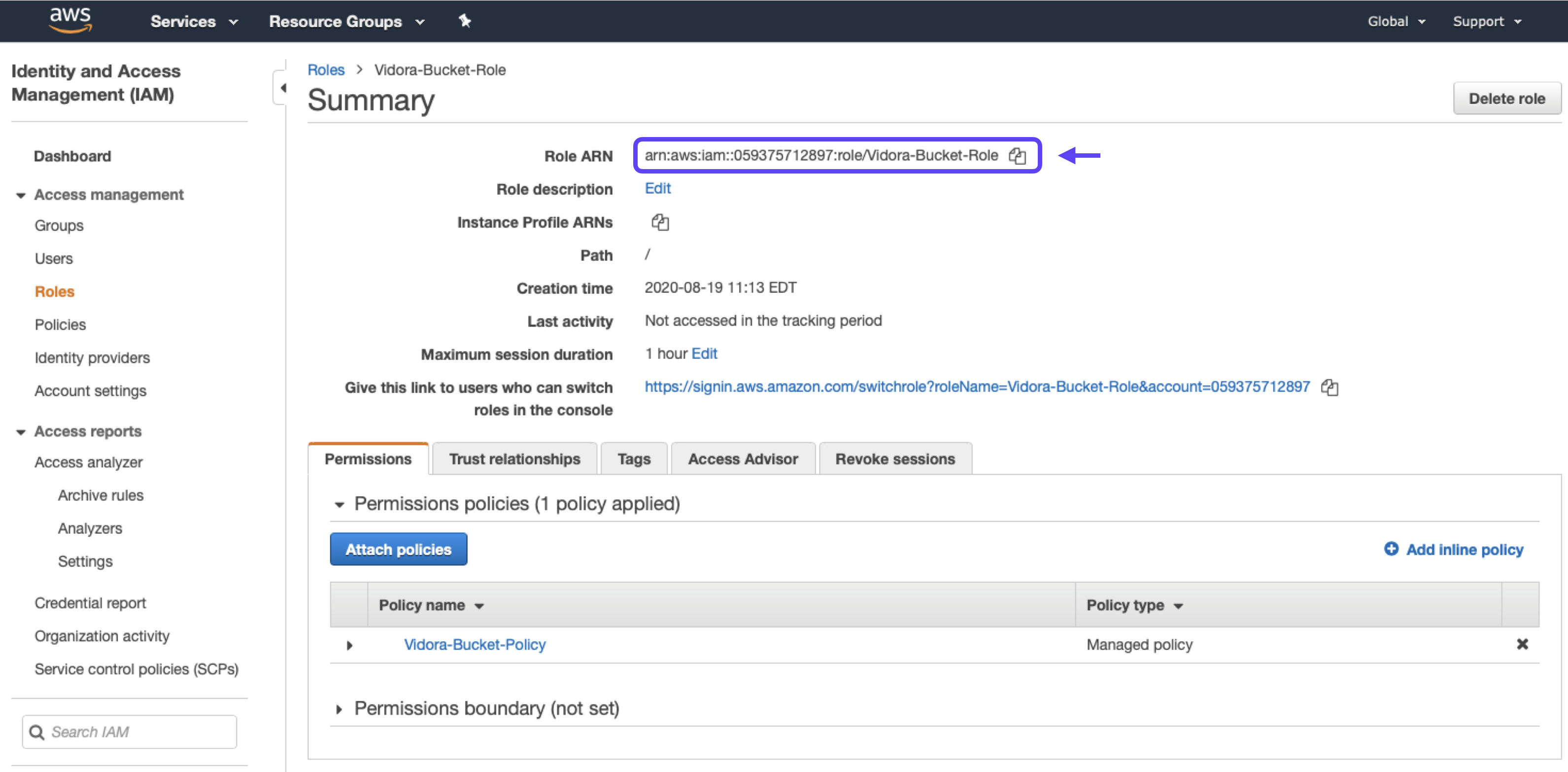
7. Click into your newly created role, and make note of the Role ARN – you will need to enter this in Cortex before activating your integration.
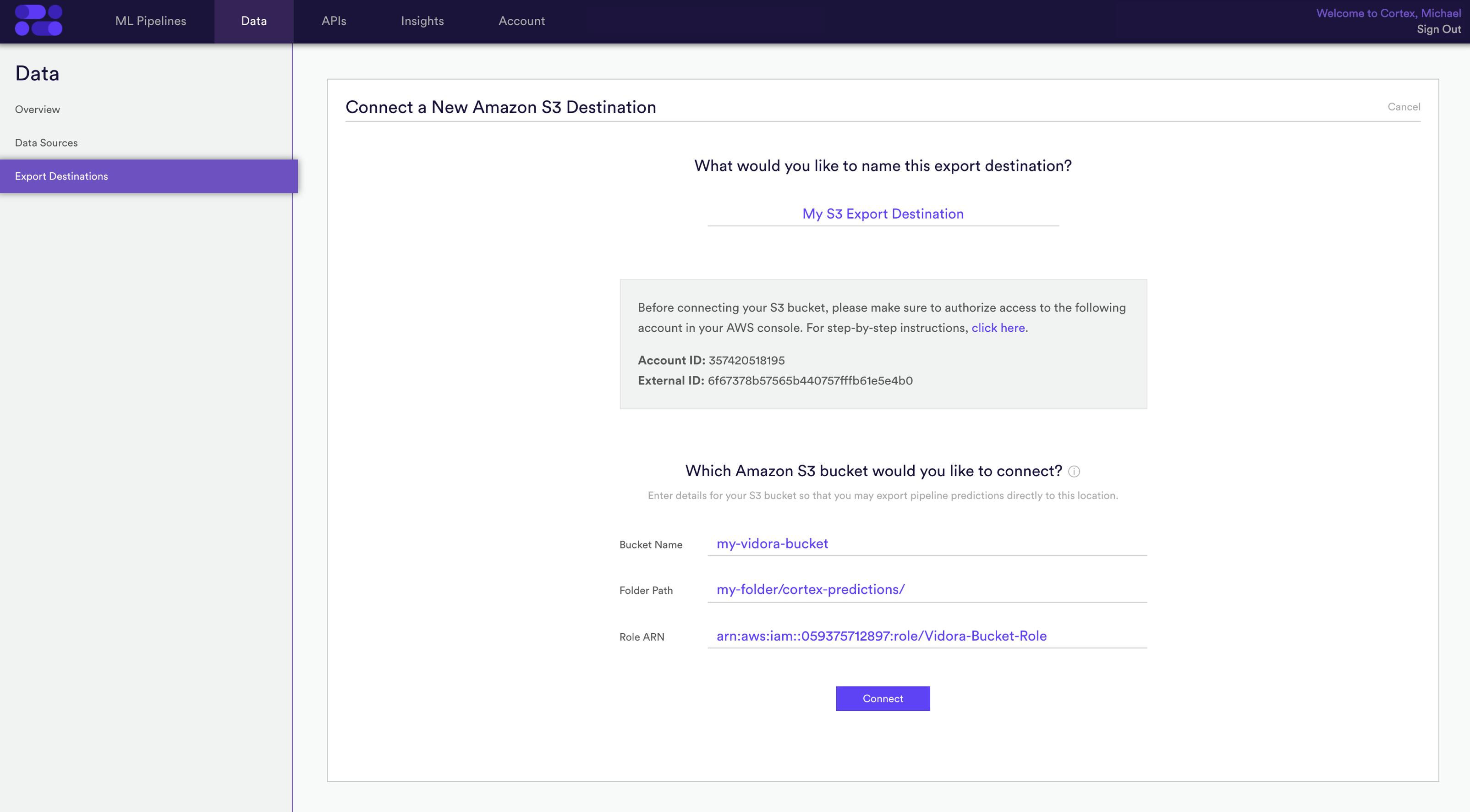
Step 4: Enter Bucket Details
Once you’ve authorized Cortex to access the bucket, head back to your Cortex account. Enter the name and folder path of your S3 bucket, as well as the ARN for the role that you just created. See below for examples.
Step 5: Activate the Connection
After you’ve entered your bucket details, hit “Connect” to activate the integration. Cortex will automatically test whether the connection is valid before creating the Export Destination.
Exporting Predictions to this Destination
Once your Export Destination has been connected, predictions from any Machine Learning Pipeline may be exported directly into your S3 bucket. To do this, create a Prediction Export and specify that results should be copied to your S3 Export Destination.
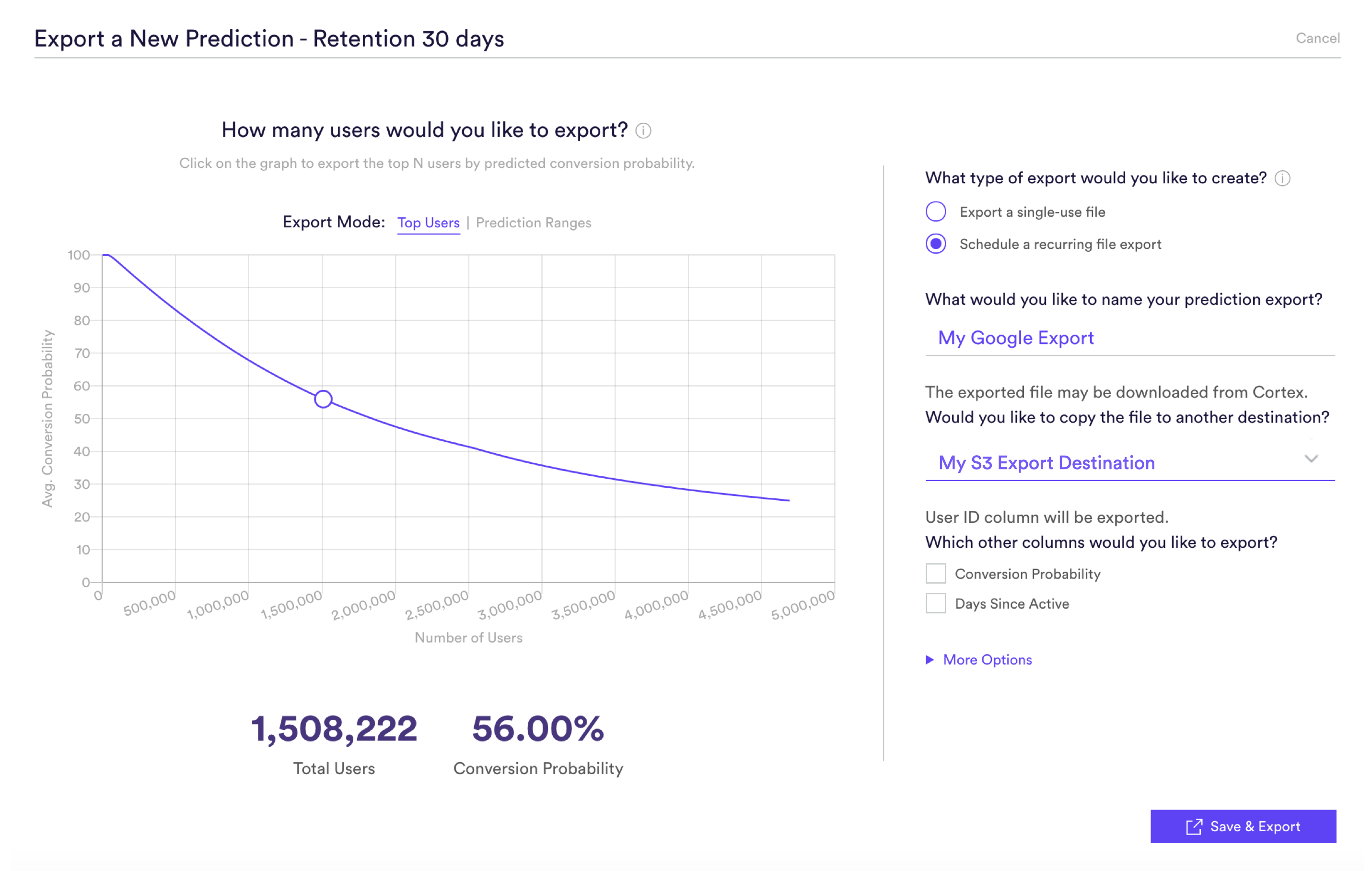
Predictions will be delivered to this S3 bucket in a sub-folder named using the Pipeline ID, while the file itself will be named using the Prediction Export ID. You may use the Pipelines API to match these IDs to their corresponding Pipeline and Prediction Export in Cortex.
Upload Template:
s3://<Bucket Name>/<Folder Path>/pipeline_<Pipeline ID>/export_<Prediction Export ID>.csv.gz
The below example shows what a final upload location might look like. The predictions file uploaded to this location will always contain results from the most recent export.
Example Upload:
s3://my-vidora-bucket/my-folder/cortex-predictions/pipeline_f90819314266a344/export_vrhmjwf10b66zl9k.csv.gz
Related Links
Still have questions? Reach out to support@mparticle.com for more info!